[k8s] KodeKloud Practice test - OS UPgrades
Q1. Let us explore the environment first. How many nodes do you see in the cluster?
A1. 2

Q2. How many applications do you see hosted on the cluster? Check the number of deployments in the default namespace.
A2. 1
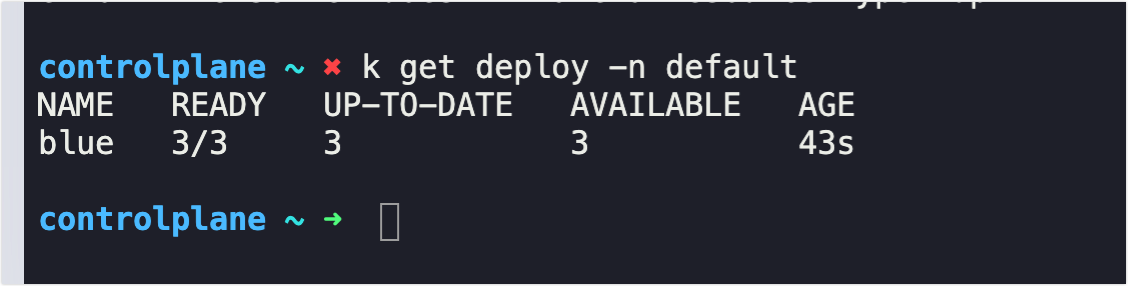
Q3. Which nodes are the applications hosted on?
A3. controlplane, node01

Q4. We need to take node01 out for maintenance. Empty the node of all applications and mark it unschedulable.
- Node node01 Unschedulable
- Pods evicted from node01
A4.
1. 먼저 cordon 설정을 한다. kubectl cordon node01
- cordon을 하게 되면 아래와 같이 node01의 상태에 대해 ScheduleingDisabled라고 나온다.
- 그런 다음 현재 node01에 배포되어 있는 pod에 대해서 eviction을 해야한다.
NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME
controlplane Ready control-plane 38m v1.24.0 10.37.81.3 <none> Ubuntu 18.04.6 LTS 5.4.0-1092-gcp containerd://1.6.6
node01 Ready,SchedulingDisabled <none> 38m v1.24.0 10.37.81.6 <none> Ubuntu 18.04.6 LTS 5.4.0-1092-gcp containerd://1.6.62. node01에 있는 pod를 다른 node로 옮긴다. kubectl drain node01 --ignore-daemonsets=true
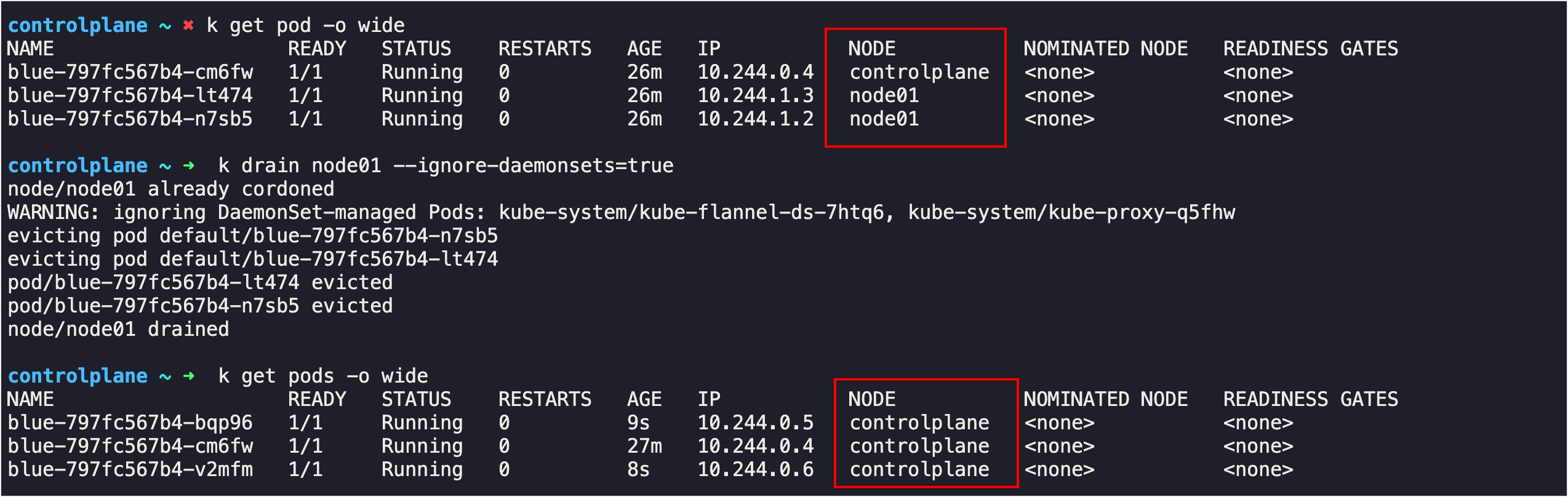
drain을 할 때, --ignore-daemonsets=true 옵션을 주었다. 만약 해당 옵션 없이 drain을 할 경우 daemonset으로 배포되는 pod가 있을 경우 실패를 한다. daemonset이라고 하는것은 각 node별로 필수로 설치되어야하는 pod를 배포하기 위해서 하는것이다.
근데 drain으로 A node의 pod을 B로 옮겨도 daemonset에 의해서 다시 A node로 pod가 배포되기 때문에 실패하는것이다.
cordon : 지정된 노드에 더이상 포드들이 스케줄링되서 실행되지 않도록 한다.
drain : 노드 관리를 위해서 지정된 노드에 있는 포드들을 다른곳으로 이동시키는 명령이다.
Q5. What nodes are the apps on now?
A5. controlplane, Q4에 의해 blue pod가 모두 이동되었다.
Q6. The maintenance tasks have been completed. Configure the node node01 to be schedulable again.
A6. kubectl get uncordon node01
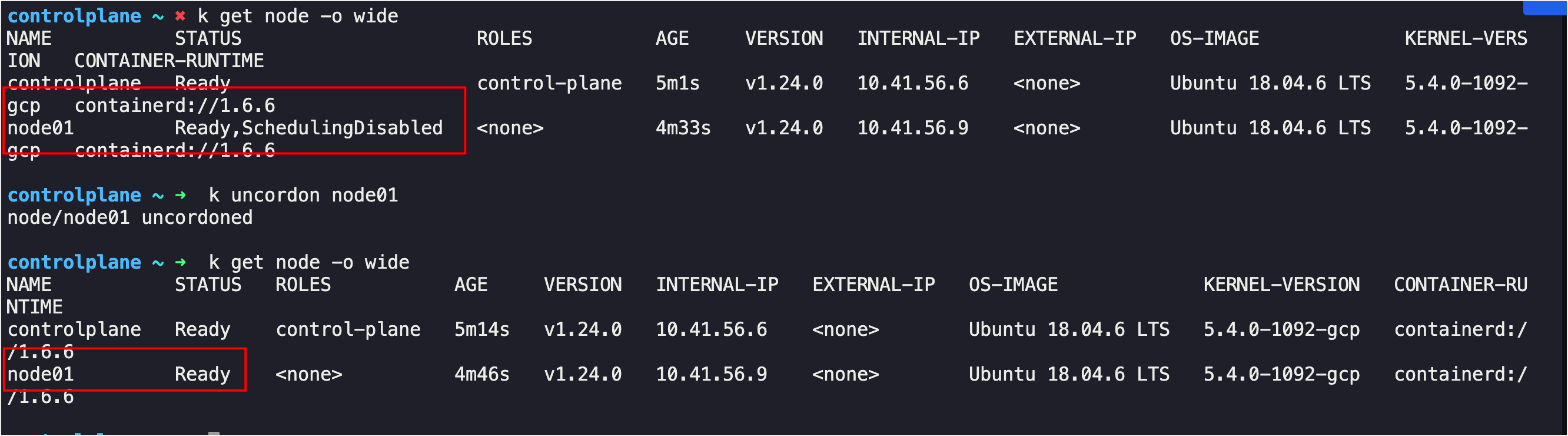
Q7. How many pods are scheduled on node01 now?
A7. 0
Q8. Why are there no pods on node01?
A8. node01이 cordon될 때 모두 다른 node로 이동되었다. uncordon을 한다고해서 pod가 돌아오는게 아니다.
Q9. Why are the pods placed on the controlplane node? Check the controlplane node details.
A9. controlplane node does not have any taints
Q10. Time travelling to the next maintenance window…
A10. ???
Q11. We need to carry out a maintenance activity on node01 again. Try draining the node again using the same command as before: kubectl drain node01 --ignore-daemonsets Did that work?
A11. no
Q12. Why did the drain command fail on node01? It worked the first time!
A12. there is a pod in node01 which is not part of a replicaset
Q13. What is the name of the POD hosted on node01 that is not part of a replicaset?
A13. hr-app
Q14. What would happen to hr-app if node01 is drained forcefully? Try it and see for yourself.
A14. hr-app pod is delete

Q15. Oops! We did not want to do that! hr-app is a critical application that should not be destroyed. We have now reverted back to the previous state and re-deployed hr-app as a deployment.
A15. OK
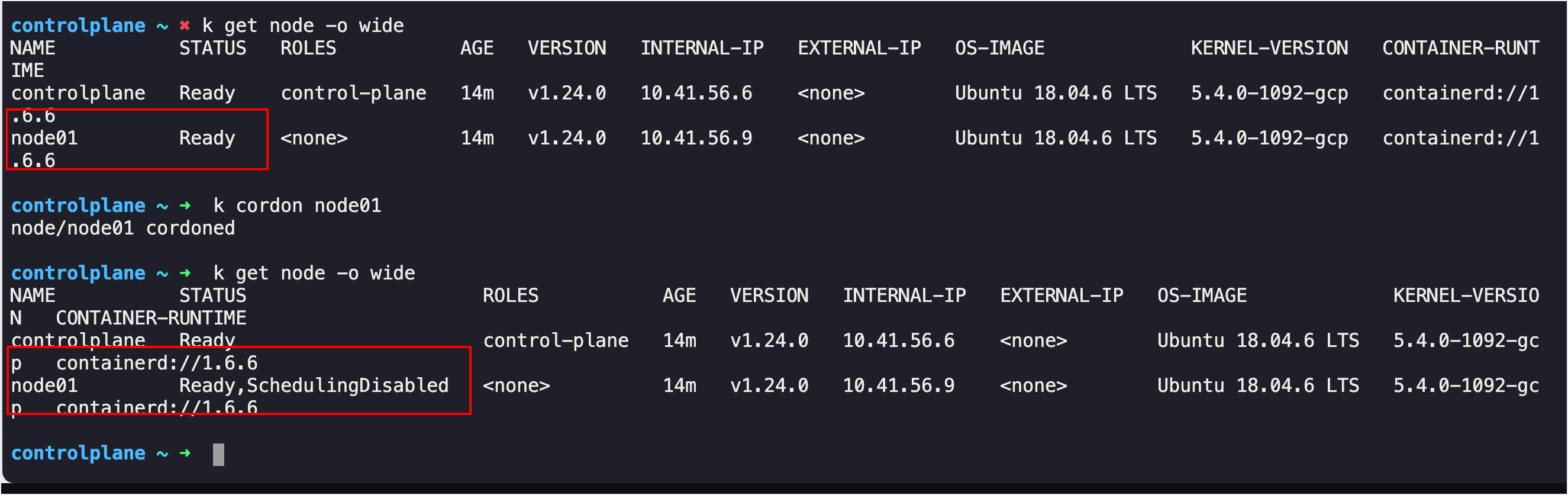
Q16. hr-app is a critical app and we do not want it to be removed and we do not want to schedule any more pods on node01. Mark node01 as unschedulable so that no new pods are scheduled on this node. Make sure that hr-app is not affected.
- Node01 Unschedulable
- hr-app still running on node01?
A17. kubectl cordon node01
이번 연습문제에서는 주로 cordon과 drain에 대해서 공부해보았다.
위에서 정리했지만 cordon은 node에 더이상 스케줄링하지 않을 때 사용하며, 사용 방법은 kubectl cordon <nodename> 이다.
cordon 이후 kubectl get node -o wide을 하면 내가 cordon한 node에 대해서는 schedulingdisable로 상태가 바뀐다.
그리고 drain은 현재 cordon 또는 기타 다른 사유로 node의 pod를 다시 node로 옮길 때 사용한다. 근데, daemonset이 있을 경우 drain 명령어 시 에러가 발생하므로 이때는 --ignore-daemonsets=true를 붙여준다!!