[AWS][AI] AWS Bedrock KnowledgeBase 사용 방법
아래 게시물에서 AI에 대해서 짧게 나마 공부하였고, 그래서 어떻게 구현할 수 있을까? 관심을 가지게되었다.
[AI] 요즘은 안하는 사람이 없다는 Gen AI, 나도 해보자.
요즘 뉴스, 유튜브를 보면 첫째도 AI, 둘째도 AI, 셋째도 AI이다. 그만큼 AI가 화두이고, 최신 트렌드인것은 분명하다.그렇다면 Gen AI가 무엇일까? 나름대로 정의하고 이걸 내재화할 수 있을까에 대
dobby-isfree.tistory.com
그리고 AWS Bedrock을 이용하면 아주 쉽게 AI를 자사 서비스에 녹일 수 있다. 그냥 Bedrock을 사용하면 공개 데이터를 기반으로 하기 때문에 특정 주제 또는 자사 서비스 특화 정보에 대해서는 사용하기 어려운 점이 있었다.
근데!! AWS Bedrock KnowledgeBase 기능이 출시되었다!! 아주 쉽게 RAG를 구현할 수 있는 서비스이다.
이전에는 RAG를 구현하려면 직접 데이터를 벡터화해서 Opensearch 또는 기타 다른 데이터베이스 임베딩해야 했기 때문에 허들이 있었으나, 이제는 콘솔 클릭 몇번만으로 데이터 벡터화 -> 임베딩까지 아주 쉽게 완성할 수 있다.
AWS Bedrock KnowledgeBase란?
Bedrock KnowledgeBase는 23년 12월 출시된 완전관리형 RAG 서비스이다.
- RAG은 검색 증강 생성으로 응답을 생성하기 전에, 신뢰할 수 있는 지식 베이스를 참조하도록 하는 프로세스이다.
- 쉽게 말하면 사용자가 질의를 하고, 응답을 만들 때 응답에 참고할 수 있는 데이터를 추가로 넣어주는것이다.
Bedrock KnowledgeBase(이하 Bedrock KB)가 없을 때는 데이터 파싱 -> 벡터화 -> 임베딩을 손수 했어야 했고,
데이터가 추가될 때 마다 적절한 Index에 다시 임베딩을 해야했기 때문에 초기 진입장벽이 있었다.
- 실제로 처음에는 Langchain을 통해서 Opensearch에 직접 임베딩하려고 했으나, 데이터를 전처리해야 하고
- 데이터 필드에 따라서 서로 다르게 파싱해야하고 고려해야 할 사항이 많아서 구현은 저 멀리 남겨두었었다..
그러다가 Bedrock KB 서비스가 출시되었고 위에서 말했듯이 완전관리형 서비스이다.
완전관리형 서비스이기 때문에 콘솔 몇번으로 구성할 수 있고 AWS SDK를 이용하면 구현하는것도 어렵지 않다.

Bedrock Knowledge 사용방법
완전관리형 서비스인만큼 사용방법 또한 매우 간단하고 직관적이다.
24.10월 기준으로 S3와 웹 크롤러를 기본으로 외부 데이터를 사용할 수 있으나, 최근에는 Confluence 등 Preview도 많이 생겼다.
먼저 Bedrock KB의 이름과 IAM 이름을 지정해주면 된다. 실제 구현할 때는 KB ID를 사용하기 때문에 KB 이름은 사실상 큰 의미없다.
그리고 IAM은 기존 역할을 사용해도 되나, 새로 만들면 필요한 권한까지 자동으로 넣어주기 때문에 새로 만드는것을 추천한다.

그 다음에는 S3 위치를 선택하고, 파싱 모델과 청크 전략을 선택하면 된다.
파싱 모델은 데이터를 청크로 만들 때 사용할 모델을 뜻한다. Haiku 보다 Sonnet이 성능이 좋다고 알려져서 Sonnet을 선택했다.
테스트는 기본 청킹 전략을 사용했고, 이는 최대 토큰을 300개까지로 구분해서 청크를 만들게 된다.
- 청크는 RAG 품질에 아주 큰 영향을 끼친다.
- 청크가 작으면 작을수록 세밀한 검색을 되나 그만큼 작은 데이터로만 응답을 하기 때문에 잘못된 응답을 할 수 있다.
- 그래서 이를 보완하기 위해서 Parent-Child 청크 전략을 선택하면 조금 더 좋은 품질의 응답을 얻을 수있다.

이제 임베딩할 모델을 선택하면 된다. 한글 데이터를 사용할 예정이기 때문에 Titan 모델을 사용했고 가장 최근에 나온 v2를 사용했다.
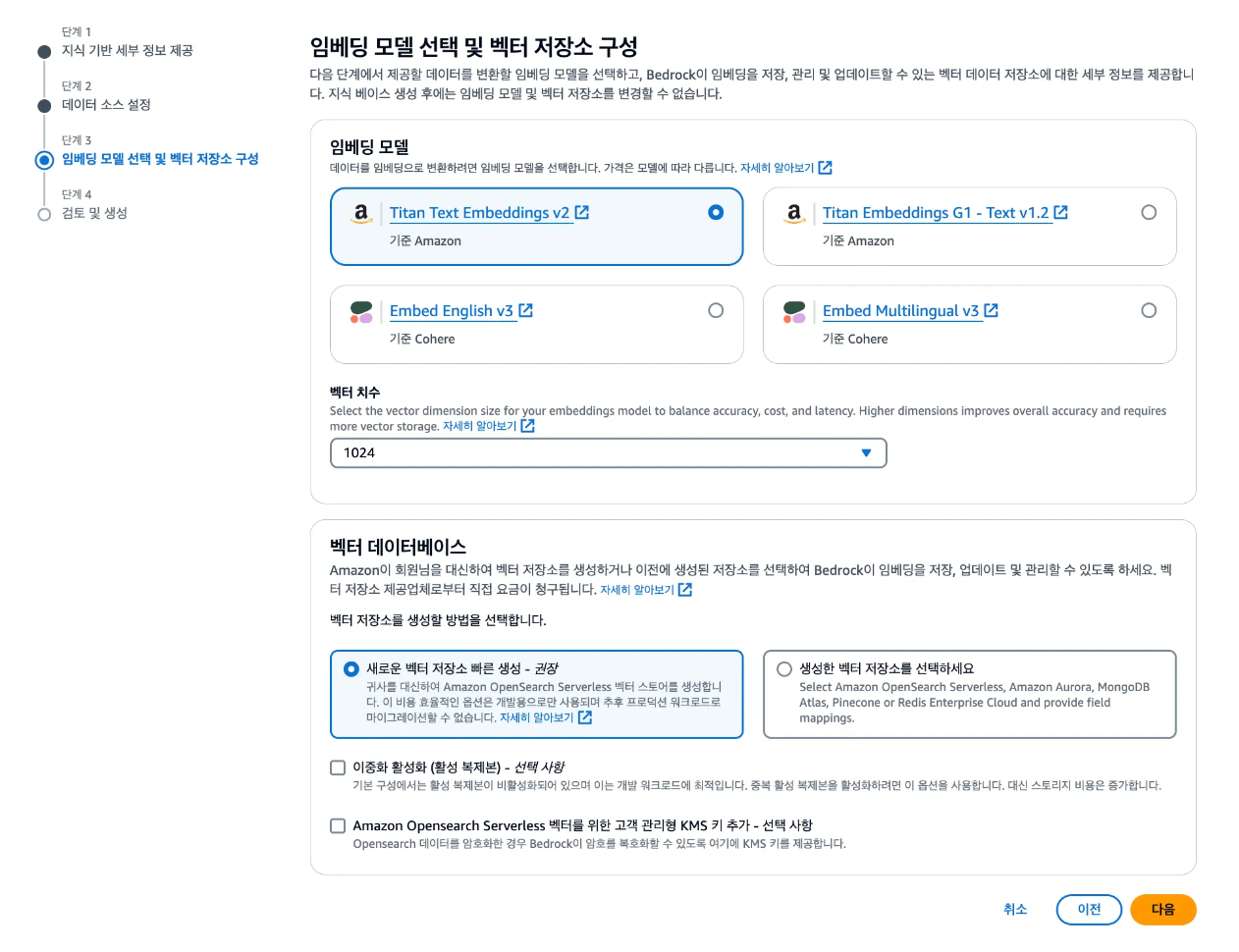
그리고 다음을 누르면 이제 끝난것이다. 그러면 기본적으로 내가 지정한 S3의 데이터를 가지고 데이터 임베딩을 할 수 있다.
S3에 데이터만 올렸다고 해서 완료가 되는것이 아니라 S3 Sync를 해야한다.
데이터양에 따라서 시간이 다르겠지만, 시간이 크게 오래 걸리지는 않는다.
그리고 최초 1번만 S3 Sync를 하면 그 이후에는 증분으로만 Sync를 하기 때문에 시간이 더욱 적게 걸린다.
- 증분이기 때문에 최초에만 Bedrock Token을 많이 사용하고, 그 이후에는 Token 사용량이 작다.
- 즉, 최초에는 임베딩하느라 비용이 많이 들고, 그 이후에는 임베딩 비용이 크지 않다.
S3 Sync는 크론탭과 같이 정해진 시간에 할 수도 있으며, EventBridege+Lambda를 통해서 특정 이벤트를 기준으로 할 수도 있다.

S3 Sync를 하게 되면, 몇개의 파일을 임베딩했는지 알 수 있고 언제 마지막으로 Sync했는지도 알 수 있다.

지금까지의 내용에 대해서 전체적인 도식도는 아래와 같다.
- S3에 데이터를 업로드 하면 -> 파싱모델로 적절한 크기로 청크를 만든 다음에 -> 임베딩 모델로 벡터화 시켜서 -> Opensearch Serverless에 임베딩 된다.

그러면 이후 Bedrock에 Prompt를 전달할 때는 RetrieveAndGenerator API를 통해서 임베딩한 데이터에서 가장 유사도 높은 문서를 찾고, 이를 Context에 추가하여 Bedrock한테 전달하기 때문에 풍부한 응답을 얻을 수 있다.
Bedrock 프롬프트 엔지니어링
KB를 만들었다면, 콘솔 화면 우측 상단에서 테스트를 해볼 수 있다. 테스트를 해서 최적화 프롬프트를 찾으면 된다.
만약에 별도 프롬프트를 정하지 않으면 좀 밋밋하게(?) 응답을 준다.

하지만, 프롬프트 엔지니어링을 적용하여 페르소나를 정의해주면 내가 원하는 것에 맞게 조금 더 커스텀된 응답을 얻을 수 있다.
AI 서비스가 처음 각광받았을 때 프롬프트 엔지니어링 채용건을 몇건 봤었는데 이처럼 프롬프트에 따라서 전혀 다른 컨셉의 응답을 줄 수 있고, 심지어 전혀 다른 응답을 얻기도 한다.
최근에는 어떤 글을 봤는데 GPT 3.5 + 파인 튜닝보다 Claude 3.5 Sonnet + 프롬프트의 응답 품질이 훨씬 좋다는 글을 보았다.
- 실제로 구현했을 때도 프롬프트를 어떻게 넣고, 어떤 페르소나로 정의하느냐에 따라서 완전히 다른 응답을 준다.

AWS를 사용해보면 정말 무섭게 빠르게 변하고, 정말 사용하기 편하다는걸 느낀다.
AWS 내부적으로 어떻게 구현되어 있는지는 잘 알지 못하지만, 콘솔 몇번으로 GPT와 같은 서비스를 구현할 수 있다.
(물론 품질은 많이 다르겠지만ㅎㅎㅎ)
다음에는 Bedrock KB를 이용해서 실제 어떻게 구현해야 하는지 알아보도록 하자!!
끝!