
첫번째 여정 게시물에서 왜 SaaS 솔루션에서 Self-hosted로 전환하는것을 고민하고 PoC 하는지에 대해 간략하게 설명했다.
이번 게시물에서는 Self-hosted 기술스택으로 선택한 LGTM 중에서 PLG 스택에 대해 정리하려고 한다.
[LGTM] Observability 기술스택 변경 여정 첫번째
현재 Obserability 기술스택 재직중인 회사에서는 설립 초창기부터 Newrelic을 사용해서 Observability를 확보하고 있었다. Observability 란? Rudolf E. Kálmán이 최초로 도입했다고 알려져있다. "오직 시스템의
dobby-isfree.tistory.com
PLG 스택이란
PLG는 Promtail + Loki + Grafana의 앞글자만 따서 부르는 로그 적재 시스템에 대한 기술스택이다.
PLG는 모두 Grafana 재단에서 개발한 오픈소스 도구이며, 각 요소에 대해 간략하게만 설명하면 다음과 같다.
- Promtail
- 로그 수집기이다. 수집한 로그 데이터를 Loki에 전달하며 레이블과 메타데이터를 함께 저장한다.
- Loki
- 오픈소스 로그 저장소이다. 로그 데이터를 효율적으로 검색/분석할 수 있게 해주며 일반적으로 Promtail을 통해 수집된 로그를 수신하고 저장하는 역할을 한다. 또한 로그 데이터는 시계열 데이터베이스에 저장하며 다른 시스템과 다르게 레이블을 색인해서 빠르게 검색이 가능하도록 한다.
- Grafana
- 대시보드 및 시각화 플랫폼이다. Loki와 연계하여 저장된 로그 데이터를 시각화하여 표현한다.
모두 Grafana 재단에서 관리하는 시스템이기 때문에 서로 연계가 잘 되어 있다.
Promtail에서는 client url 주소를 Loki URL만 잡으면 로그 전송이 끝난다. 그리고 Grafana에서는 Loki URL만 입력하면 Data Source 선택이 가능하다.
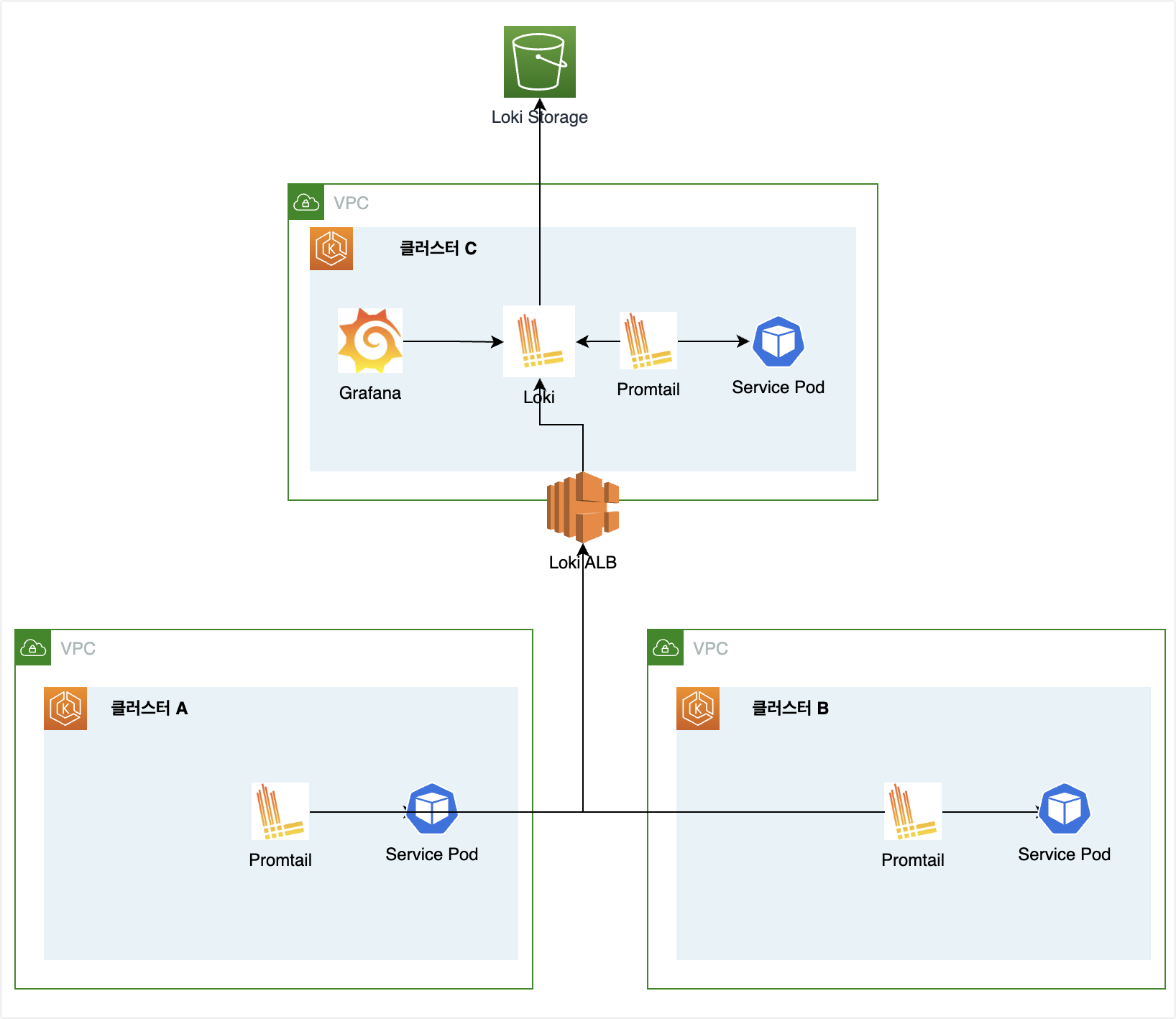
PLG 스택 구성도
어떻게 구성할지는 여러가지 선택이 있겠지만, 필자는 아래와 같이 중앙 시스템에서 로그를 수집하는 구성으로 했다.
EKS를 사용하고 있기 때문에 클러스터 A, B에서는 Promtail만 배포하고 Loki Ingress host로 로그를 전송하도록 했다.
그리고 클러스터C에는 중앙 시스템으로 Loki + Grafana가 설치되어 있는 클러스터이다.
이때 Loki에서는 외부 Object Storage를 지원하기 때문에 S3를 외부 저장소로 지정해서 사용했다.
- 쉽게 말하면 과거 로그를 S3에 저장하고 필요에 따라서 쿼리하고 결과를 불러오기 때문에 Loki에서는 큰 Storage가 필요없다.
PLG 스택 설치 방법
설치 방법에 대해서는 할말이 많다 :( Grafna helm-charts를 보면 Loki-stack이 있고, Loki-distribution chart가 존재한다.
Loki-stack charts는 single mode라서 단일 pod에서 모든 컴포넌트의 역할을 하고, Loki-distribution은 MSA의 형태로 배포된다.
이중에서 나는 Loki-stack charts를 사용해서 배포하는 방법을 선택했다.
왜냐하면 Loki-distribution charts에는 아직 문제점이 많았다.
일단 distribution charts가 나온지 얼마 안되서 실제 charts랑 docs랑 다른 부분이 많았다. 특히 S3 Object Stroage를 사용할 때..
- Loki를 사용하고자 했던 큰 이유 중 하나가 Object Storage 인데, docs랑 내용이 달라서 설치에 시간 소요를 많이 했다.
- 그리고 distribution은 MSA 구조로 되어 있어서 대용량 처리에 부합하지만, 필자는 큰 데이터가 아니라서 loki-stack을 선택했다.
중앙 클러스터 helm values
중앙 클러스터에서는 각 클러스터의 Loki endpoint가 되므로 Promtail + Loki + Grafana가 모두 설치되어야 한다.
필자는 아래의 values에서 일부 값을 바꿔서 배포했다. 하지만 이것도 정답은 없기때문에 상황에 맞춰서 변경해서 사용하면 된다.
### Loki ###
loki:
enabled: true
resources:
limits:
cpu: 1000m
memory: 512Mi
requests:
cpu: 1000m
memory: 512Mi
ingress:
enabled: true
annotations:
kubernetes.io/ingress.class: alb
alb.ingress.kubernetes.io/target-type: ip
alb.ingress.kubernetes.io/certificate-arn: xxxxx <- 각자 맞는 ARN을 넣으면 된다.
alb.ingress.kubernetes.io/wafv2-acl-arn: xxxxx <- 각자 맞는 ARN을 넣으면 된다.
alb.ingress.kubernetes.io/inbound-cidrs: 0.0.0.0/0
alb.ingress.kubernetes.io/scheme: internet-facing
hosts:
- host: loki.xxx.xx.xx <- 각자 맞는 Host URL을 넣으면 된다.
paths:
- /
isDefault: true
url: http://{{(include "loki.serviceName" .)}}:{{ .Values.loki.service.port }}
readinessProbe:
httpGet:
path: /ready
port: http-metrics
initialDelaySeconds: 45
livenessProbe:
httpGet:
path: /ready
port: http-metrics
initialDelaySeconds: 45
datasource:
jsonData: "{}"
uid: ""
serviceAccountName: loki-sa
serviceAccount:
create: true
name: loki-sa
annotations:
eks.amazonaws.com/role-arn: xxxxx <- 각자 맞는 IAM을 넣으면 된다. IAM 에는 S3 Put,Get,Delete 권한이 필요하다.
auth_enabled: false
commonConfig:
path_prefix: /var/loki
replication_factor: 1
#### 이 부분 아래부터는 Docs를 참고해서 상황에 맞춰서 넣는것을 추천한다. ####
compactor:
apply_retention_interval: 1h
compaction_interval: 720m
retention_delete_worker_count: 500
retention_enabled: true
retention_deletes_enabled: true
shared_store: s3
retention_period: 672h
working_directory: /data
config:
ingester:
chunk_idle_period: 1h
chunk_retain_period: 30s
max_chunk_age: 1h
chunk_target_size: 1572864
limits_config:
enforce_metric_name: false
reject_old_samples: true
reject_old_samples_max_age: 168h
max_cache_freshness_per_query: 10m
schema_config:
configs:
- from: 2020-05-15
store: boltdb-shipper
object_store: s3
schema: v11
index:
period: 24h
prefix: loki_index_
storage_config:
aws:
region: ap-northeast-2
bucketnames: sandbox-loki-storage-069889557760-ap-northeast-2
s3forcepathstyle: false
boltdb_shipper:
shared_store: s3
### promtail ###
promtail:
enabled: true
config:
logLevel: info
serverPort: 3101
clients:
- url: http://{{ .Release.Name }}:3100/loki/api/v1/push
snippets:
pipelineStages:
- drop:
source: "namespace"
expression: "(kube-system|kube-node-lease)" <- Namespace 기준으로 수집을 제외할 대상이다.
extraRelabelConfigs:
- source_labels: []
action: replace
target_label: cluster_name
replacement: Cluster C <- 다수의 Promtail에서 로그를 수집할 때 클러스터 기준이 되는 Labels을 추가하는것이다.
### grafana ###
grafana:
enabled: true
persistence:
enabled: true
size: 10Gi
ingress:
enabled: true
annotations:
kubernetes.io/ingress.class: alb
alb.ingress.kubernetes.io/target-type: ip
alb.ingress.kubernetes.io/certificate-arn: xxxxx <- 각자 맞는 ARN을 넣으면 된다.
alb.ingress.kubernetes.io/wafv2-acl-arn: xxxxx <- 각자 맞는 ARN을 넣으면 된다.
alb.ingress.kubernetes.io/inbound-cidrs: 0.0.0.0/0
alb.ingress.kubernetes.io/scheme: internet-facing
path: /
hosts:
- grafana.xxx.xx.xx <- 각자 맞는 Host URL을 넣으면 된다.
sidecar:
datasources:
label: ""
labelValue: ""
enabled: true
maxLines: 1000
image:
tag: 8.3.5
users:
default_theme: dark중앙 클러스터를 배포할 때 가장 중요한것은 loki.compactor, loki.config 하위 파라미터들을 어떻게 설정할지 고민하는것이다.
그리고 S3를 외부 스토리지로 사용하고자 할 때는 loki.config.storage_config를 설정하는것이 중요하므로 꼭 확인하기 바란다.
helm upgrade로 배포하게 되면 Promtail은 daemonset으로 배포가 되고, Loki는 statefulset, Grafana는 Deployment로 배포된다
- Promtail은 daemonset으로 배포되기 때문에 Taint 있는 노드가 있다면 Tolerations을 추가해줘야 한다.
helm upgrade --install loki grafana/loki-stack -f ./devops-sandbox.yaml로그 수집 클러스터 helm values
로그 수집 대상이 되는 클러스터에서는 Promtail만 설치하고, 로그를 중앙 클러스터의 Loki에 전송만 하면 된다.
그렇기에 Loki, Grafana는 false로 설정해야 한다. 그리고 Promtail clients.url에서는 중앙 클러스터의 Loki Ingress URL이 필요하다.
- 중앙 클러스터와 로그 수집 클러스터가 서로 다른 VPC에 있을 경우, Loki Ingress의 Security Group 설정을 해야한다.
그리도 cluster_name Labels을 추가하는것을 추천한다. 만약 다른 구분자가 있다면 추가 안해도 된다.
- 그렇지 않으면 각 클러스터를 구분할 수 있는 구분자가 없기 때문에 Grafana에서 조회하기 까다로워진다.
만약 기존에 Fluentd + Fluentbit를 사용하고 있다면 Promtail을 사용하지 않아도 된다.
Fluentbit에서 Destination으로 Loki 또는 S3, Newrelic 등을 설정할 수 있으므로 조금 더 확장성이 좋은건 Fluentbit 시리즈이다.
### Loki ###
loki:
enabled: false
### promtail ###
promtail:
enabled: true
config:
logLevel: info
serverPort: 3101
clients:
- url: https://loki.xxx.xx.xx/loki/api/v1/push <- 중앙 클러스터에서 설정한 Loki URL이 된다.
snippets:
pipelineStages:
- drop:
source: "namespace"
expression: "(kube-system|kube-node-lease)" <- Namespace 기준으로 수집을 제외할 대상이다.
extraRelabelConfigs:
- source_labels: []
action: replace
target_label: cluster_name
replacement: Cluster A <- 다수의 Promtail에서 로그를 수집할 때 클러스터 기준이 되는 Labels을 추가하는것이다.
### grafana ###
grafana:
enabled: false설치하는 방법은 위와 같이 helm upgrade를 하면 되고 values 파일만 변경해주면 된다.
Loki, Grafana 모두 False 이기 때문에 Promtail만 daemonset으로 배포된다.
Grafana 설정, DataSource
기본적으로 위 helm-charts values를 배포하면 Grafana에서 중앙 클러스터에 위치한 Loki를 Default DataSrouce로 설정되어 있기 때문에 별도 설정해줄 필요는 없다.
- 만약 안되어 있다면 Loki URL을 참고해서 넣으면 되기 때문에 어렵지 않다.
결론
다시 한번 말하지만 필자는 Loki-stack helm-charts를 사용했지만, 반드시 해당 charts를 사용해야 하는건 아니다.
최근 Grafana에서는 Loki-stack, Mimir-stack charts에서 *-distribution charts로 넘어가는 추세이다.
회사와 팀의 리소스 상황에 따라서 사용하면 된다.
필자의 회사에서는 비중요 시스템으로 분류하는 클러스터를 기존 Newrelic -> PLG 스택으로 로그 적재 시스템을 변경했다.
그리고 변경 전/후 Newrelic 데이터 적재량을 비교해보면 약 35%의 로그량이 줄었고 결과적으로 Newrelic 요금도 줄었다.
- 직접적으로 Newrelic 비용이 줄었다고 표현할 수는 없지만, 재계약때 줄여서 계약을 할 예정이다.
- 물론 PLG 스택을 배포하는 Pod 및 운영코스트를 별도 산정해보진 않았지만 크진 않다.
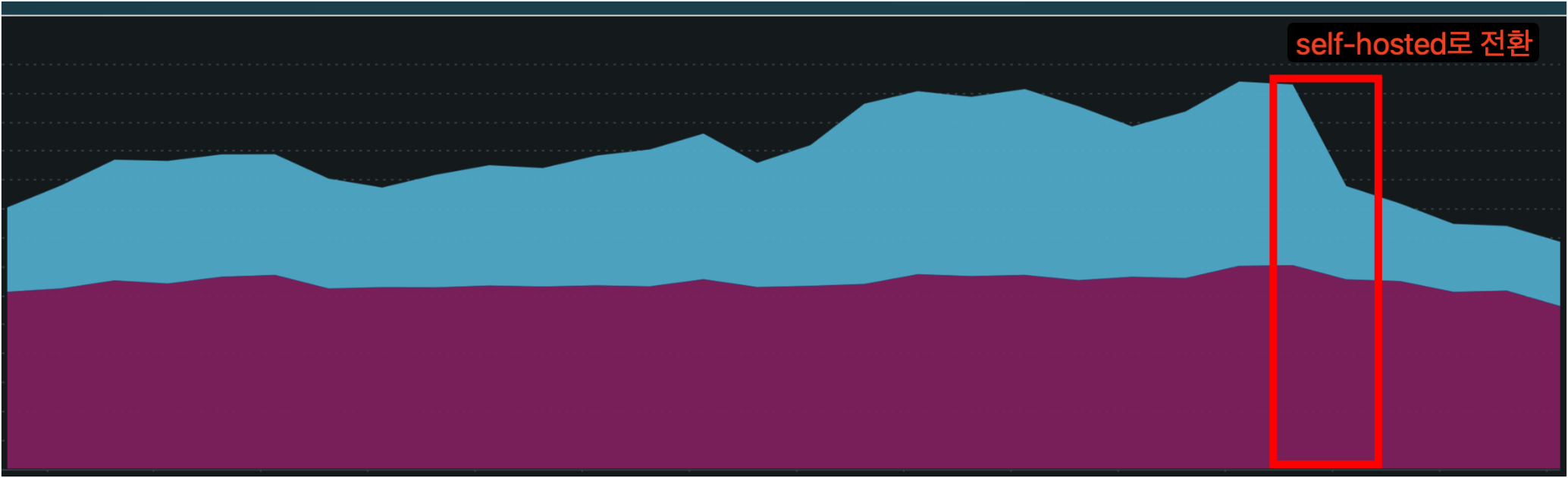
이것만 보더라도 PLG, Self-hosted로 로그를 이관하는것에 대한 당위성과 효과는 있다고 생각한다.
기존에 로그 중요성은 떨어지나, 혹시나.. 있을지 모르는 상황에 대비해서 로그 적재하던 것을 Self-hosted로 전환해서 비용 효율성을 높였다고 생각한다.
최근? Finops 자격증을 취득하면서 가장 공감되는 구절이 있다.
Finops는 비용을 줄이는 행위가 아니라, 비즈니스 가치를 극대화하는것이다.
비즈니스 목표, 가치에 비용을 맞춤으로서 불필요한 아키텍처를 찾아내고 효율화하는것이다.
말 그대로다. A 서비스에서 매출이 100만원 일지라도 Newrelic으로 20만원을 사용한다면 비즈니스 가치는 80만원밖에 되지 않는다.
하지만 이런 Finops 활동을 통해 비용을 효율화 한다면 A 서비스 매출이 오롯이 모두 비즈니스 가치에 반영된다.
Finops 활동은 멀리 있는 것이 아니라, 주변에서 당연하게 사용하고 있는것이 정말 당연하게 사용해야 될 것인지?
다른 아키텍처로 개선할 수 없는지? 고민해보고 PoC해보고 상황에 맞춰서 적용하는것이다.
Devops, Finops 엔지니어분들 다들 힘내세요!!
끄읏!!
'기술 이모저모 > [Ops] Devops' 카테고리의 다른 글
| [Finops] AMD vs ARM, AWS Graviton Node (1) | 2024.09.22 |
|---|---|
| [AI] 요즘은 안하는 사람이 없다는 Gen AI, 나도 해보자. (0) | 2024.06.30 |
| [LGTM] Observability 기술스택 변경 여정 첫번째 (0) | 2024.03.09 |
| [MSA] MSA 구조란 무엇이고, 왜 다들 열광하는가? (2) | 2024.01.07 |
| [Vault] Vault 백업/복구, 신규 클러스터 마이그레이션 방법 (0) | 2023.12.24 |