
이번달부터 가시다님이 주관하시는 Cilium 스터디를 진행하게되었다.
지난주부터 8주간 진행되는 스터디로, 각 주차별로 스터디했던 내용을 나만의 방법으로 이해하고자 정리하려고 한다.
스터디 1주차는 실습 환경 구성과 Cilium에 대한 간단한 설명과 설치를 하는 주차이다.
- 아직까지는 부담스럽지 않은 주차이다. 하지만 시간이 갈수록 점점 어려운 개념들이 많이 나오겠지..
- 사실 이번 주차에서도 트래픽 흐름에 대해서는 잘 모르는 분야여서 많이 찾아봤는데, 아직까지도 명확하게는 잘 모르겠다.
- 지금까지 커널을 생각해본적이 많이 없다. 트래픽은 알아서 흐르구나.로 생각했지 트래픽이 어떻게 흐른다.를 고민해본적이 없다.
실습 환경 구성
먼저 실습 환경은 Vagrant + Virtualbox로 구성한다.
- Vagrant는 가상환경을 만들고, 쉽게 생성하고 관리하는 역할이고
- Virtualbox는 가상환경을 만들어주는 하이퍼바이저이다.
개인적으로 K8s 테스트를 할떄는 kind를 많이 이용했는데 kind에서는 일부 제약이 있다고 해서 이번에는 Vagrant로 진행한다고 한다.
기본적으로 설치하는 방법은 매우 간단하다. 나는 별도 버전 정보를 주지 않았기때문에 latest 버전으로 설치를 했다.
## virtualbox Install
```bash
brew install --cask virtualbox
vBoxManage -v
7.1.10r169112
```
## vagrant Install
```bash
brew install --cask vagrant
vagrant --version
Vagrant 2.4.7
```
그리고 위와 설명한것과 같이 Vagrant는 가상환경을 생성하고 관리하는 시스템이다.
그렇기 때문에 어떤 구성요소로 가상환경을 만들지 Vagrantfile이 필요하다. 그리고 vagrant init을 하면 기본 포맷이 만들어진다.
중요한건 Vagrant에서 가상환경을 만들 때 프로바이더에서 OS 이미지를 제공해줘야 하는데, 예시처럼 hashicorp에서 많이 제공해준다.
- https://portal.cloud.hashicorp.com/vagrant/discover/rockylinux/9
```bash
vagrant init hashicorp/bionic64
```
---Vagrantfile---
Vagrant.configure("2") do |config|
config.vm.box = "hashicorp/bionic64"
end
그리고 스터디에서는 아래와 같은 구성요소로 Kubernetes를 구성하였다.
마스터 노드 1대와 워커노드 2대, 총 3대로 Kubernetes를 구성하였으며 K8s 버전은 1.33을 사용하고 있다.
- 노드 이미지는 utuntu-24로 했지만, 주석처리한것과 같이 hashicorp에서 제공하고 있는 rockyliniux를 사용할 수도 있다.
# Variables
K8SV = '1.33.2-1.1' # Kubernetes Version : apt list -a kubelet , ex) 1.32.5-1.1
CONTAINERDV = '1.7.27-1' # Containerd Version : apt list -a containerd.io , ex) 1.6.33-1
N = 2 # max number of worker nodes
# Base Image https://portal.cloud.hashicorp.com/vagrant/discover/bento/ubuntu-24.04
## Rocky linux Image https://portal.cloud.hashicorp.com/vagrant/discover/rockylinux
BOX_IMAGE = "bento/ubuntu-24.04"
BOX_VERSION = "202502.21.0"
# BOX_IMAGE = "rockylinux/9"
# BOX_VERSION = "6.0.0"
Vagrant.configure("2") do |config|
#-ControlPlane Node
config.vm.define "k8s-ctr" do |subconfig|
subconfig.vm.box = BOX_IMAGE
subconfig.vm.box_version = BOX_VERSION
subconfig.vm.provider "virtualbox" do |vb|
vb.customize ["modifyvm", :id, "--groups", "/Cilium-Lab"]
vb.customize ["modifyvm", :id, "--nicpromisc2", "allow-all"]
vb.name = "k8s-ctr"
vb.cpus = 2
vb.memory = 2048
vb.linked_clone = true
end
subconfig.vm.host_name = "k8s-ctr"
subconfig.vm.network "private_network", ip: "192.168.10.100"
subconfig.vm.network "forwarded_port", guest: 22, host: 60000, auto_correct: true, id: "ssh"
subconfig.vm.synced_folder "./", "/vagrant", disabled: true
subconfig.vm.provision "shell", path: "https://raw.githubusercontent.com/gasida/vagrant-lab/refs/heads/main/cilium-study/1w/init_cfg.sh", args: [ K8SV, CONTAINERDV]
subconfig.vm.provision "shell", path: "https://raw.githubusercontent.com/gasida/vagrant-lab/refs/heads/main/cilium-study/1w/k8s-ctr.sh", args: [ N ]
end
#-Worker Nodes Subnet1
(1..N).each do |i|
config.vm.define "k8s-w#{i}" do |subconfig|
subconfig.vm.box = BOX_IMAGE
subconfig.vm.box_version = BOX_VERSION
subconfig.vm.provider "virtualbox" do |vb|
vb.customize ["modifyvm", :id, "--groups", "/Cilium-Lab"]
vb.customize ["modifyvm", :id, "--nicpromisc2", "allow-all"]
vb.name = "k8s-w#{i}"
vb.cpus = 2
vb.memory = 1536
vb.linked_clone = true
end
subconfig.vm.host_name = "k8s-w#{i}"
subconfig.vm.network "private_network", ip: "192.168.10.10#{i}"
subconfig.vm.network "forwarded_port", guest: 22, host: "6000#{i}", auto_correct: true, id: "ssh"
subconfig.vm.synced_folder "./", "/vagrant", disabled: true
subconfig.vm.provision "shell", path: "https://raw.githubusercontent.com/gasida/vagrant-lab/refs/heads/main/cilium-study/1w/init_cfg.sh", args: [ K8SV, CONTAINERDV]
subconfig.vm.provision "shell", path: "https://raw.githubusercontent.com/gasida/vagrant-lab/refs/heads/main/cilium-study/1w/k8s-w.sh"
end
end
endControl Plane
그리고 control plane이 되는 k8s-ctr을 살펴보면, 여러가지 활동을 하나 중요한것은 k8s-ctr.sh을 실행하는것이다
k8s-ctr.sh을 보면 TASK 1이 있는데, TASK 1에서 kubeadm init이 실행된다.
kubeadm init을 하면
- /etc/kubernetes/pki 경로에 인증서와 키 파일이 만들어진다.
- /etc/kubernetes/manifest 경로에 etcd/kube-apiserver/controller-manager/scheduler의 yaml이 생성되고
- 이를 kubelet이 인지하고 containerd를 통해 pod이 만들어지고 비로서 control plane으로서 동작하게 된다.
echo "[TASK 1] Initial Kubernetes"
kubeadm init --token 123456.1234567890123456 --token-ttl 0 --pod-network-cidr=10.244.0.0/16 --service-cidr=10.96.0.0/16 --apiserver-advertise-address=192.168.10.100 --cri-socket=unix:///run/containerd/containerd.sock >/dev/null 2>&1
또는 아래와 같이 kubeadm init file을 만든 다음에 init을 해도 된다. 보통 yaml을 만들어서 init을 하는것이 일반적인 방법이고
init 이후에 token list로 token을 확인하고 Worker join을 하면 된다.
``` kubeadm-init-config.yaml
apiVersion: kubeadm.k8s.io/v1beta3
kind: InitConfiguration
localAPIEndpoint:
advertiseAddress: 192.168.10.100
bindPort: 6443
nodeRegistration:
criSocket: unix:///run/containerd/containerd.sock
---
apiVersion: kubeadm.k8s.io/v1beta3
kind: ClusterConfiguration
networking:
podSubnet: 10.244.0.0/16
serviceSubnet: 10.96.0.0/16
```
```
kubeadm init --config kubeadm-init-config.yaml
kubeadm token list
```
Worker Node
그리고 Worker 노드에서는 단순히 control plane에서 만든 kubeadm token을 가지고 join을 하는것밖에 없다.
- 운영환경 또는 보안을 신경써야하는곳이라면 Cacert를 넣어야 하겠지만, 테스트에서는 이를 skip하는 옵션을 넣어서 했다.
echo "[TASK 1] K8S Controlplane Join"
kubeadm join --token 123456.1234567890123456 --discovery-token-unsafe-skip-ca-verification 192.168.10.100:6443 >/dev/null 2>&1
그리고 Control Plane과 마찬가지로 Worker Node도 kubeadm으로 쉽게 클러스터에 조인할 수 있다.
```kubeadm-config.yaml
apiVersion: kubeadm.k8s.io/v1beta3
kind: JoinConfiguration
discovery:
bootstrapToken:
apiServerEndpoint: "192.168.10.100:6443"
token: "123456.1234567890123456"
# unsafeSkipCAVerification: true
# kubeadm join을 해서 얻은 마스터 노드의 ca cert값의 공개키를 검증하는 작업인데, 없어도 되나 있으면 중간자 공격을 방지할 수 있다
caCertHashes:
- "sha256:9b2453ae661f2a119628edbc3921672b671e0533c7cea627d6e2b084da2260cb"
nodeRegistration:
kubeletExtraArgs:
node-ip: "192.168.10.102"
```
```
kubeadm join --config kubeadm-config.yaml
```
이렇게까지만 하면, 아래와 같은 구성의 클러스터를 구성할 수 있다.
하지만 클러스터를 구성했을뿐 CNI가 없어서 각 노드는 NotReady 상태이고 CNI를 설치해야 실질적으로 사용할 수 있다.
아! 그리고 Pod IP대역은 10.244로 정했고, Node끼리도 원활하게 통신하기 위해서 아래와 같이 192.168 대역으로 변경이 필요하다.
```
NODEIP=$(ip -4 addr show eth1 | grep -oP '(?<=inet\s)\d+(\.\d+){3}')
sed -i "s/^\(KUBELET_KUBEADM_ARGS=\"\)/\1--node-ip=${NODEIP} /" /var/lib/kubelet/kubeadm-flags.env
```
systemctl daemon-reexec && systemctl restart kubelet


Cilium

Cilium 개념
Cilium은 기존의 eBPF 기술을 적용하여, 커널에 프로그램을 실행하여 유연하고 확정성 그리고 보안성 등을 높이고자하는 CNI이다.
- 아직은 정확하게 와닿지는 않는다. eBPF가 무엇인지? 그래서 Non Cillium이랑 체감하는 차이가 무엇인지
- 차이가 무엇인지. 이제부터 차차 알아가는것을 목적으로 한다.
기존에 iptables는 많은 문제가 있었다. Cilium에서는 기존의 iptables 방식을 벗어나고자하는 시도가 있다.
1. 가장 큰 문제점으로 단일 트랜잭션으로 Rule을 업데이트해야 한다.
- 쉽게 말하면, Rule을 추가하거나/제거하는 방식이 아니고 적용하고자 하는것을 전체를 Save -> Apply 하는 방식이다.
(AWS WAF IPRuleSet이 이렇게 적용된다.)
- 그렇기때문에 자연스럽게 규칙이 많을수록 비효율성이 커지고,
- 쿠버네티스와 같이 서비스 엔드포인트가 자주 변경되는 환경에서는 iptables 업데이트만을 위해서 많은 시스템 자원을 사용하여 대규모 환경에서는 병목이 될 수 있다.
2. IP/Port 기반의 Rule이 기본이 된다. 즉, L7 계층에 대한 Rule이 부족하다.
- iptables를 보면 알겠지만 기본적으로 L3, L4 계층에 IP/Port 기반으로 라우팅 정책이 되어 있다.
- 하지만 최근 서비스 환경에서는 L7 레이어를 이애하고 트래픽을 제어하는것이 중요한대, iptables에서는 제약이 있다.
3. Rule이 순차적으로 적용되며, 모든 Connection은 체인 형태로 구성되어 있다.
- iptables는 상단위 Rule부터 순차적으로 적용된다. 그렇기때문에 Rule을 추가하거나 트러블슈팅을 할 때 어려움이 있다.
- 또한, 상단의 Rule부터 순차적으로 매칭되는지 비교를 하기 때문에 Rule이 많으면 많을수록 그만큼 성능이 저하되는 문제점이 있다.

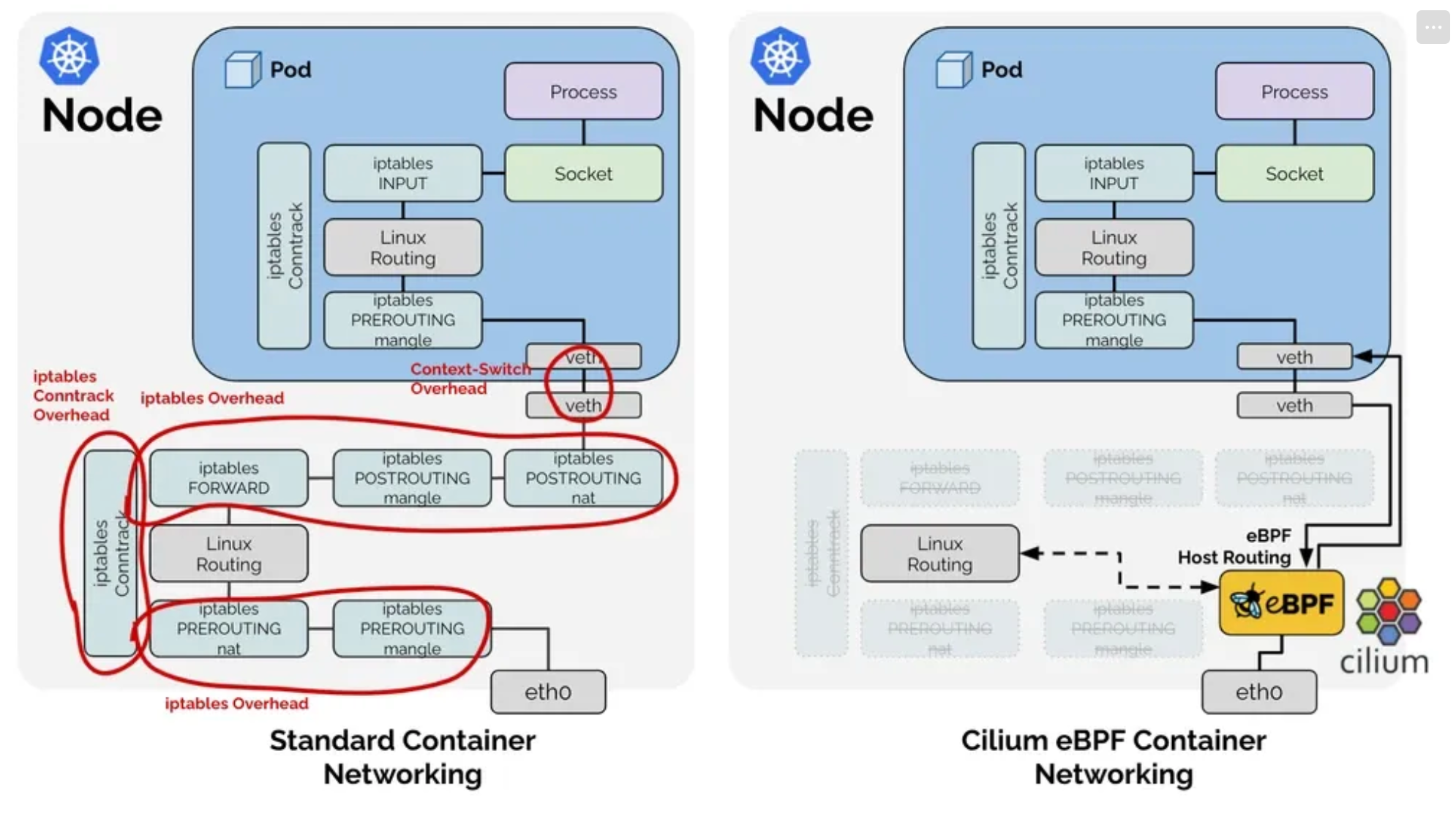
또한 제일 처음에 Cilium은 커널에 프로그램을 실행하여 트래픽을 제어한다고 표현했는데, 위 그림을 보면 알 수 있다.
기존의 CNI에서는 전통적인 리눅스 네트워크 스택을 사용하며, 각 스택을 건너뛰거나 변경하기 어려웠다.
하지만 Cilium은 tcx같은 Hook에 접근하여 패킷을 필터링하거나,
XDP와 같은 특수한 모드에서는 인터페이스간 네트워크제어도 가능하다.
커널 환경에 접근해서 Hook에 접근하고 필요한 동작을 한다. 이것이 Cilium의 가장 큰 차이점이라고 생각한다.
Cilium 설치
설치하는 방법은 Helm으로 설치를 할 수 있다.
- 스터디에서는 Flannel CNI을 먼저 설치하고, Cilium으로 넘어가는것으로 스터디하였으나 Flannel CNI 설치는 스킵한다.
helm repo add cilium https://helm.cilium.io/
---
helm install cilium cilium/cilium --version 1.17.5 --namespace kube-system \
# k8s-ctr의 node IP를 작성한다.
--set k8sServiceHost=192.168.10.100 --set k8sServicePort=6443 \
# Cilium에서 Pod IP Range을 알고, 이를 사용하는것이다.
--set ipam.mode="cluster-pool" \
--set kubeProxyReplacement=true \
# CNI에서 Pod에 할당하는 IP 대역이다.
--set ipam.operator.clusterPoolIPv4PodCIDRList={"172.20.0.0/16"} \
# ipv4NativeRoutingCIDR, autoDirectNodeRoutes 보통 같이 설정한다.
# 이것은 172.20.0.0/16에 대해서는 같은 Pod IP대역이므로 별도 NAT를 하지 않고
# 바로 Pod 인터페이스로 라우팅하는 설정이다.
--set ipv4NativeRoutingCIDR=172.20.0.0/16 \
--set autoDirectNodeRoutes=true \
# 보통 native가 directRoutring을 하겠다는 의미이다.
--set routingMode=native \
--set endpointRoutes.enabled=true \
--set installNoConntrackIptablesRules=true \
--set bpf.masquerade=true \
--set ipv6.enabled=false
그리고 만약에 위 내용을 Helm Values로 설치하고자 한다면, 아래와 같이 Values를 만들어서 사용하면 된다.
(⎈|HomeLab:kube-system) root@k8s-ctr:~# helm get values cilium
USER-SUPPLIED VALUES:
autoDirectNodeRoutes: true
bpf:
masquerade: true
debug:
enabled: true
endpointRoutes:
enabled: true
installNoConntrackIptablesRules: true
ipam:
mode: cluster-pool
operator:
clusterPoolIPv4PodCIDRList:
- 172.20.0.0/16
ipv4NativeRoutingCIDR: 172.20.0.0/16
ipv6:
enabled: false
k8sServiceHost: 192.168.10.100
k8sServicePort: 6443
kubeProxyReplacement: true
routingMode: native
그리고 pod을 생성하면 위 values에서 정의한 "clusterPoolIPv4PodCIDRList" IP 대역으로 Pod IP가 할당된다.

Cilium 트래픽 확인
위에서 Cilium을 routingMode: native + autoDirectNodeRoutes=true로 설치했다.
즉, 같은 Pod IP(172.20.0.0/16)에 대해서는 별도 NAT를 하지 않고(=오버헤드를 붙이지 않고) Pod IP로 라우팅하겠다는뜻이다.
실제로 테스트를 해보면 Node-1에 있는 nginx1에서 Node-2에 있는 nginx-2로 curl 요청을 하면
Node-1, Node-2에서는 트래픽이 보이지 않고, nginx-2에서 바로 nginx-1의 Pod IP로 트래픽이 확인된다!!
- 즉, 커널의 라우팅 테이블을 사용하지 않는다는것을 의미한다.
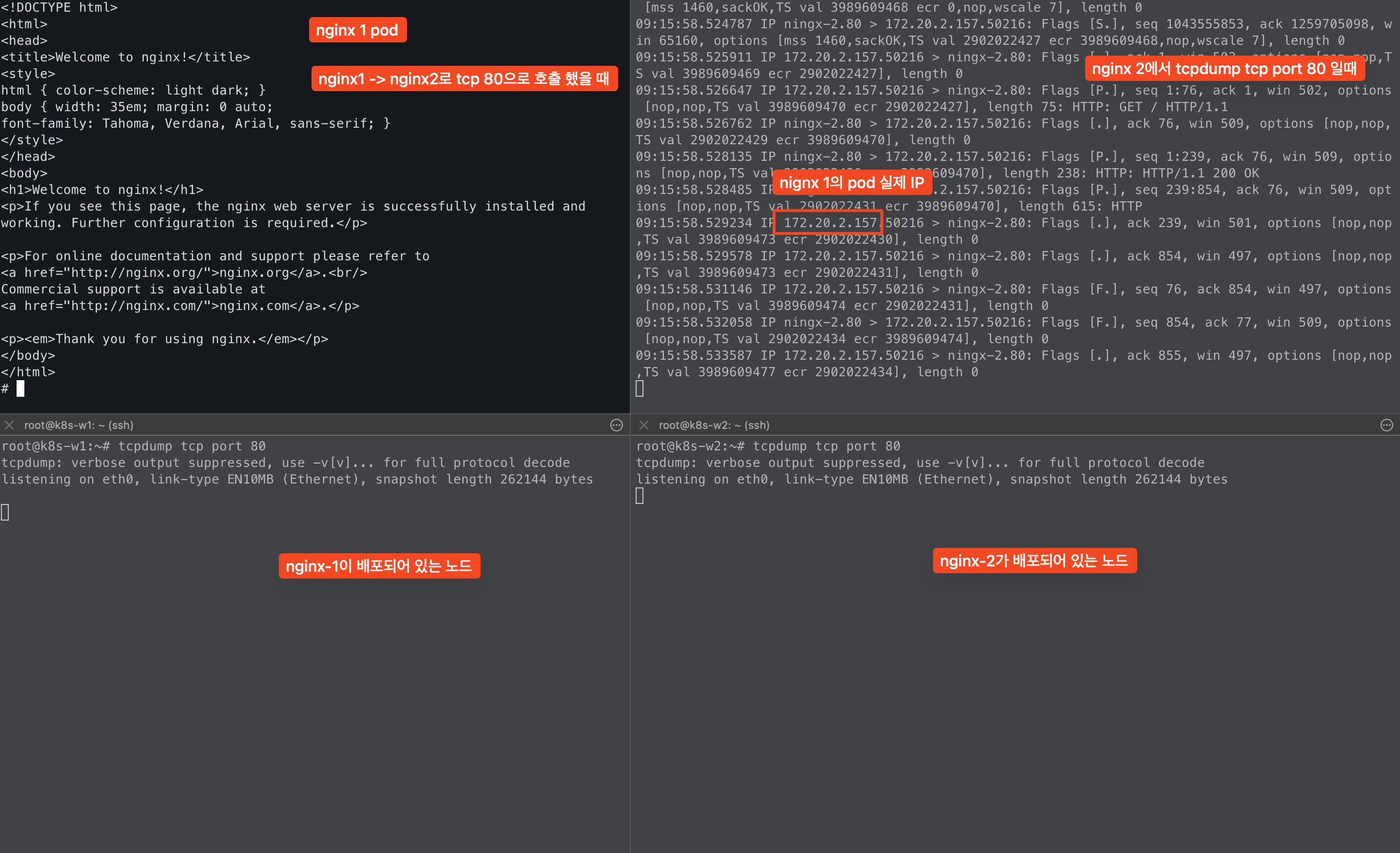
그렇다면 pod eth0와 매핑되어 있는 cilium lxc 인터페이스에서는 트래픽이 보이는걸까?
실제로 테스트를 해보면 노드에서 tcpdump를 했을 때 보이지 않았던 트래픽이 노드 lxc 인터페이스에서는 확인이 된다.
이는 cilium은 설치할 때 navite + dirctrountingmode로 설치했기 때문에 이러한 결과가 나오는것이다.
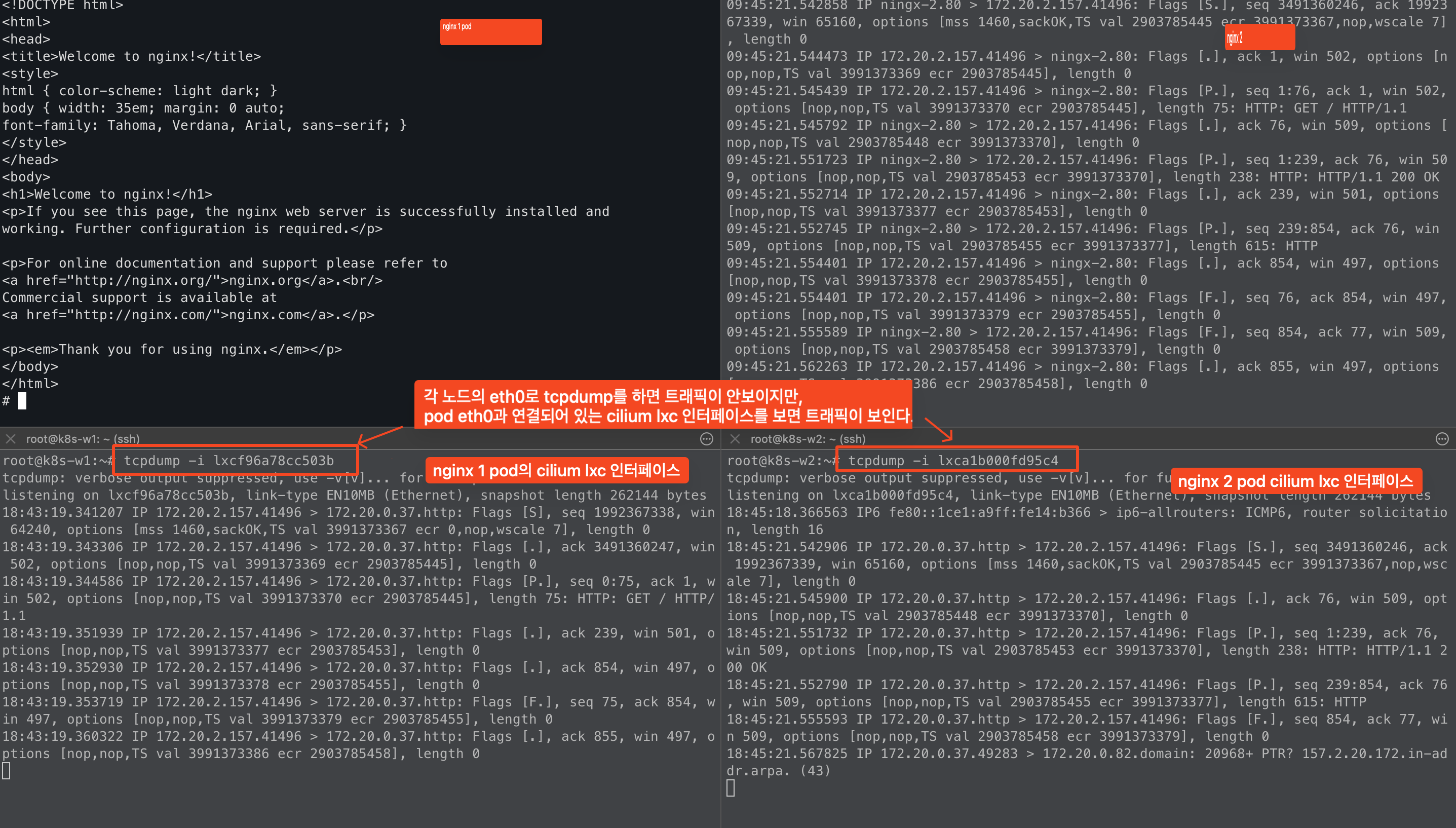
+ 확인하고자 하는 pod에 대해서 cilium endpoint id를 확인한 다음에 노드와 매핑되어 있는 lxc 인터페이스를 확인할 수 있다.
# kubectl exec -it -n kube-system ds/cilium -- cilium endpoint list
Defaulted container "cilium-agent" out of: cilium-agent, config (init), mount-cgroup (init), apply-sysctl-overwrites (init), mount-bpf-fs (init), clean-cilium-state (init), install-cni-binaries (init)
ENDPOINT POLICY (ingress) POLICY (egress) IDENTITY LABELS (source:key[=value]) IPv6 IPv4 STATUS
ENFORCEMENT ENFORCEMENT
'''
2439 Disabled Disabled 40045 k8s:io.cilium.k8s.namespace.labels.kubernetes.io/metadata.name=test 172.20.0.37 ready
k8s:io.cilium.k8s.policy.cluster=default
k8s:io.cilium.k8s.policy.serviceaccount=default
k8s:io.kubernetes.pod.namespace=test
k8s:run=ningx-2
'''
# 확인하고자 하는 pod에 대해서 cilium endpoint id를 확인한 다음에 노드와 매핑되어 있는 lxc 인터페이스를 확인할 수 있다.
# kubectl exec -it -n kube-system ds/cilium -- cilium endpoint get 2439 |grep lxc
"interface-name": "lxca1b000fd95c4",
cilium에서는 어떻게 바로 pod eth0와 연결되어 있는 lxc 인터페이스로 바로 트래픽을 보낼 수 있는것일까?
커널에 프로그램을 실행하는것이다. 기본대로라면 커널에 라우팅 테이블을 봐야한다.
cilium에서는 pod을 할당하면, pod 정보(ip, 인터페이스)를 cilium_lxc 맵에 추가한다.
그리고 목적지 ip를 확인하고 L2 헤더를 추가한다.
l2 헤더를 추가한 다음에는 목적지 pod mac 정보를 보고, lxc 인터페이스로 바로 라우팅이 되는것이다.

cilium에서 가장 핵심이 되는 내용이며, 앞으로 많이 많이 나올것 같은 내용이다.
cilium은 커널에 프로그램을 직접 심어서, Hook을 걸고 필요에 따라서 원하는 동작을 하도록 하는것이다!
cilium docs를 보면 아주 길지만 한눈에 알아보기는 쉽지 않다.
그리고 평상시에 커널이나, 네트워크 흐름에 대해서 크게 고민해보지 않았기때문에 이번 스터디가 더욱 기대되고 재미있을것 같다.
이 글을 보실지는 모르겠지만 좋은 스터디를 마련해주신 가시다님께 감사합니다 :)

'기술 토론장 > [K8s] Kubernetes' 카테고리의 다른 글
| [Cilium][2주차] Prometheus/Grafana을 통한 Cilium 가시성 확보 (0) | 2025.07.22 |
|---|---|
| [Cilium][2주차] Hubble을 통한 Cilium Traffic 가시성 확보 (3) | 2025.07.21 |
| [k8s] helm upgrade fail, remove api 조치 방안 (2) | 2023.02.05 |
| [k8s] kubenetes coreDNS 개념정리 (0) | 2023.01.29 |
| [k8s] EKS AWS VPC CNI 정리 (0) | 2023.01.29 |