
앞선 게시물에서는 hubble을 통해서 cilium traffic에 대한 가시성 확보 방안을 살펴보았다.
[Cilium][2주차] Hubble을 통한 Cilium Traffic 가시성 확보
2주차 스터디가 진행됬다.2주차에는 Observability가 주된 스터디 내용이였다.이중에서 특히 Hubble + Promehteus + Grafna를 통해서 현재 네트워크 트래픽에 대한 지표를 수집하고 관찰하는것이 목적이다.
dobby-isfree.tistory.com
그러면 이번 게시물에서는 cilium metrics를 prometheus에서 수집해서 grafana로 시스템에 대한 가시성을 확보하는 방안에 대해서 알아보고자 한다.
실습 환경 구성
kubectl apply -f https://raw.githubusercontent.com/cilium/cilium/1.17.6/examples/kubernetes/addons/prometheus/monitoring-example.yaml
---
cat << EOF | kubectl apply -f -
apiVersion: apps/v1
kind: Deployment
metadata:
name: webpod
spec:
replicas: 2
selector:
matchLabels:
app: webpod
template:
metadata:
labels:
app: webpod
spec:
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- sample-app
topologyKey: "kubernetes.io/hostname"
containers:
- name: webpod
image: traefik/whoami
ports:
- containerPort: 80
---
apiVersion: v1
kind: Service
metadata:
name: webpod
labels:
app: webpod
spec:
selector:
app: webpod
ports:
- protocol: TCP
port: 80
targetPort: 80
type: ClusterIP
EOF
---
# k8s-ctr 노드에 curl-pod 파드 배포
cat <<EOF | kubectl apply -f -
apiVersion: v1
kind: Pod
metadata:
name: curl-pod
labels:
app: curl
spec:
nodeName: k8s-ctr
containers:
- name: curl
image: nicolaka/netshoot
command: ["tail"]
args: ["-f", "/dev/null"]
terminationGracePeriodSeconds: 0
EOF
실습 환경은 기본적으로 제공해주는 example 코드와 샘플 애플리케이션을 배포한다.
배포를 하면 기본적으로 prometheus, grafana가 배포되고, 테스트 할 수 있는 webpod가 배포된다.
그리고 prometheus, grafana에 접근하기 위해서 Nodeport로 변경한 다음에 Nodeport로 접속해서 시스템을 이용하면 된다.
# grafana, prometheus에 접근하기 위해 Svc를 NodePort로 변경한다.
kubectl patch svc -n cilium-monitoring grafana -p '{"spec": {"type": "NodePort", "ports": [{"port": 3000, "targetPort": 3000, "nodePort": 30002}]}}'
kubectl patch svc -n cilium-monitoring prometheus -p '{"spec": {"type": "NodePort", "ports": [{"port": 9090, "targetPort": 9090, "nodePort": 30001}]}}'
---
(⎈|HomeLab:cilium-monitoring) root@k8s-ctr:~# k get all
NAME READY STATUS RESTARTS AGE
pod/curl-pod 0/1 ContainerCreating 0 2s
pod/grafana-5c69859d9-g9hgw 1/1 Running 0 7m42s
pod/prometheus-6fc896bc5d-54slf 1/1 Running 0 7m42s
pod/webpod-697b545f57-cgqbz 0/1 ContainerCreating 0 3s
pod/webpod-697b545f57-v8d46 0/1 ContainerCreating 0 3s
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/grafana NodePort 10.96.211.199 <none> 3000:30002/TCP 44m
service/prometheus NodePort 10.96.205.208 <none> 9090:30001/TCP 44m
service/webpod ClusterIP 10.96.200.147 <none> 80/TCP 3s
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/grafana 1/1 1 1 7m42s
deployment.apps/prometheus 1/1 1 1 7m42s
deployment.apps/webpod 0/2 2 0 3s
NAME DESIRED CURRENT READY AGE
replicaset.apps/grafana-5c69859d9 1 1 1 7m42s
replicaset.apps/prometheus-6fc896bc5d 1 1 1 7m42s
replicaset.apps/webpod-697b545f57 2 2 0 3s
cilium은 기본적으로 prometheus metrics를 노출하지 않기 때문에, 아래와 같이 helm values를 변경해서 배포해야한다.
- prometheus.enabled : 가장 메인이 되는 cilium에서 tcp 9962로 prometheus port를 노출한다.
- operator.prometheues.enabeld : cilium-operator에서 tcp 9963로 prometheus port를 노출한다.
- hubble.metrics.endabled : hubble에서 tcp 9965로 prometheus port를 노출한다.
각각의 시스템별로 서로 다른 포트를 사용하고 있기 때문에 마찬가지로 3개의 Port가 열려있는것을 확인할 수 있다.
helm upgrade --install cilium cilium/cilium --version 1.17.6 --reuse-values \
--namespace kube-system \
--set prometheus.enabled=true \
--set operator.prometheus.enabled=true \
--set hubble.enabled=true \
--set hubble.metrics.enableOpenMetrics=true \
--set hubble.metrics.enabled="{dns,drop,tcp,flow,port-distribution,icmp,httpV2:exemplars=true;labelsContext=source_ip\,source_namespace\,source_workload\,destination_ip\,destination_namespace\,destination_workload\,traffic_direction}"
배포를 하면 cilium deamonset에 prometheus annotation이 추가되고, prometheus port를 확인하고 metrics를 수집한다.

Prometheus + Grafana
Prometheus는 흔히 많이 들어봤을것이다. Prometheus는 시계열 데이터베이스 기반의 모니터링 도구이다.
일반적으로 많이 사용되는 도구이며, Pull 방식으로 시스템 Metrics를 수집하는 목적으로 많이 사용된다.
- Metrics : 시스템 전반적인 상태를 확인할 수 있는 정량적인 지표이다. CPU, 메모리, 5XX request count
그리고 데이터와 Label을 기반으로 저장하며 PromQL로 데이터를 조회하거나 집계를 한다.
Grafana는 Prometheus와 같이 수집한 시계열 데이터를 시각화하는 플랫폼이다.
Prometheus Metrics 데이터 확인
Promethues는 Pod Annotation에 특수한 Prometheus key가 있으면 수집을 하는걸 기본으로 한다.
그래서 이미 수집을 하고 있으며, 이를 Prometheus에서 쉽게 확인할 수 있다.

또한 Prometheus Status 카테고리를 통해서 현재 수집하고 있는 시스템과 마지막 수집시간, 소요된 시간까지 확인할 수 있다.
만약 보고자하는 Metrics가 없다면 가장 먼저 1. Pod Annotation을 확인하고 2. Status에서 수집되고 있는지 확인을 하면 된다.

Grafana 데이터 확인
grafana는 시각화 플랫폼이기 때문에, 결국에는 데이터 원소스가 필요하다.
example로 배포한 yaml에서는 grafana에서 prometheus:9090 서비스로 데이터를 호출해서 사용한다.
- example에서는 1개의 데이터 소스만 가지고 있으나, 실제 운영할때는 다수의 promethues를 연결할 수 있고
- RDS, Tempo, Loki 등등 다양한 데이터 소스를 사용할 수 있다. 다양한 소스를 사용할 수 있기 때문에 그만큼 범용성이 좋다.
대시보드를 직접 만들수도 있지만, JSON Import로 대시보드를 추가할 수 있다.
그리고 grafana는 커뮤니티가 아주 활성화되어 있어서 직접 대시보드를 만들지 않더라도 쉽게 대시보드 구성이 가능하다.
- https://grafana.com/grafana/dashboards/

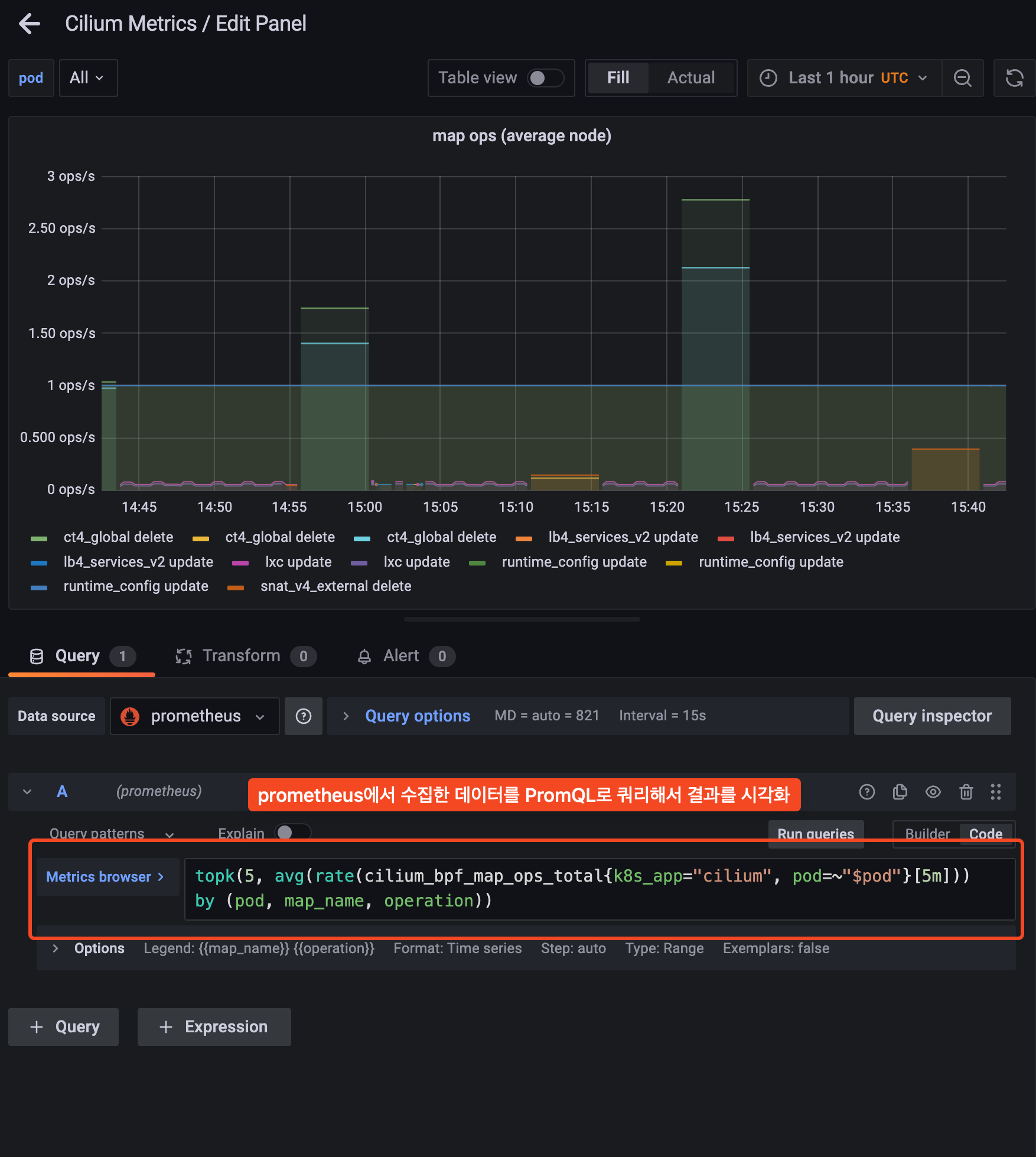
grafana가 prometheus를 소스로 하여 PromQL로 시각화하는 플랫폼이다.
그렇기 때문에 PromQL에 대한 어느정도(?)의 습득이 필요하다.
자주 사용하는 rate, sum by, topk와 같은 문법이 있다. 각 요구사항에 맞춰서 PromQL을 구성하면 된다.
grafana는 워낙 커뮤니티 활성화가 많이 되어 있는만큼 PromQL은 예시가 아주 잘 되어 있다.
- https://promlabs.com/promql-cheat-sheet/
Hubble L7 데이터 확인
L7 cnp를 적용하면 hubble에서 L7 metrcis을 노출하고, 이를 grafana로 시각화를 할 수 있다.
cat <<EOF | kubectl apply -f -
apiVersion: "cilium.io/v2"
kind: CiliumNetworkPolicy
metadata:
name: "l7-visibility"
spec:
endpointSelector:
matchLabels:
# namespace labels을 잘못 지정해서 호출이 안되서.. 왜 안되는지 한참 찾았다.
"k8s:io.kubernetes.pod.namespace": cilium-monitoring
egress:
- toPorts:
- ports:
- port: "53"
protocol: ANY # TCP, UDP 둘 다 허용
rules:
dns:
- matchPattern: "*" # 모든 도메인 조회 허용, L7 가시성 활성화
- toEndpoints:
- matchLabels:
"k8s:io.kubernetes.pod.namespace": cilium-monitoring
toPorts:
- ports:
- port: "80" # default 다른 파드의 HTTP TCP 80 요청 허용
protocol: TCP
- port: "8080" # default 다른 파드의 HTTP TCP 8080 요청 허용
protocol: TCP
rules:
http: [{}] # 모든 HTTP 요청을 허용, L7 가시성 활성화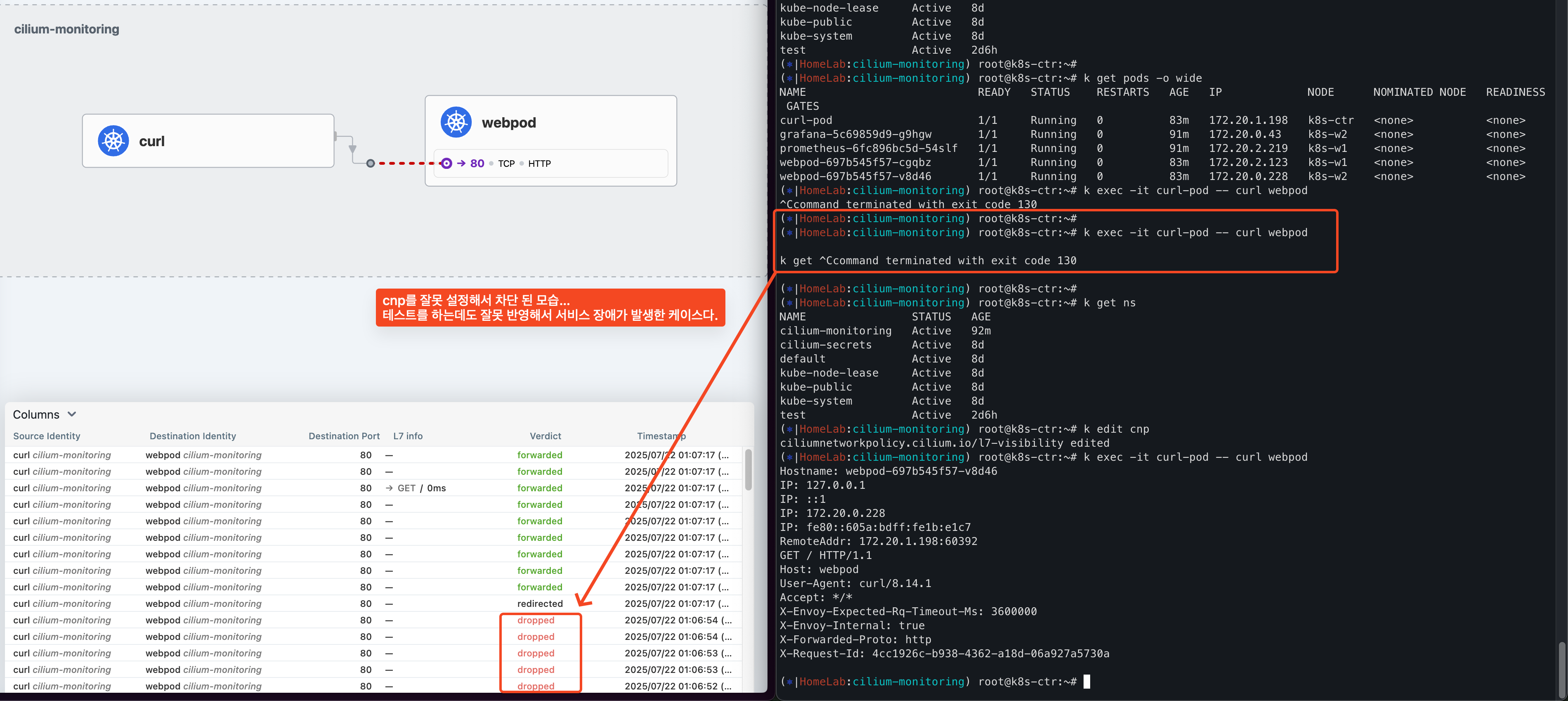
근데 여기에서 한가지 문제점이 생긴다.
L7에 대한 통제가 가능한 만큼 Path에 대한 정보가 남게된다.
그리고 이를 hubble.export 그리고 hubble observe를 통해서 확인할 수 있는 문제점이 생긴다.

cilium에서도 물론 L7 제어를 하는 만큼 민감정보 노출을 하지 않도록 옵션을 제공해주고 있다.
그리고 이를 적용하면 path param은 그대로 노출이 되나, query param은 표시가 되지 않는다.
- 보통 path param은 식별자를 위해서 사용되기 때문에 상대적으로 중요도는 낮고
- query param은 path param과 함께 key=values로 사용자의 의도에 맞도록 하기 때문에 상대적으로 중요도가 높다.
helm upgrade cilium cilium/cilium --namespace kube-system --reuse-values \
--set extraArgs="{--hubble-redact-enabled,--hubble-redact-http-urlquery}"
이번주차는 가시성 확보를 주제한 주차였다.
그래서 Hubble 그리고 Prometheus, Grafana에 대해 중점적으로 알아보았다.
현업에서 쿠버네티스 또는 시스템을 운영하면, 내가 운영하는 시스템이 이상이 없는지? 확인하는것이 필수이다.
그리고 이때 가시성 확보를 위해 반드시 사용되는게 Promethues + Grafana이다.
이것은 Cilium을 떠나서, 다양한 방면에서 사용하기 때문에 꼭꼭 숙지하고, 익힐 필요가 있는 스택이다.
이번주 수요일부터 일요일까지 해외 일정이 있어서 지금 새벽까지 스터디 내용을 정리하고 있다.
가시성 확보와 Hubble/Prometheus는 평소에 잘 해보지 않았던 주제였기 때문에 과제를 좀 더 자세하게 하고 싶었는데
화요일까지.. 스터디 정리를 해야하기에 다소(?) 정리가 부족하지 않았나 반성이 된다.
해외 일정이라 어쩔 수는 없지만.. 다음주부터는 더욱 더 박차를 가해야겠다!! 가즈아!!

'기술 토론장 > [K8s] Kubernetes' 카테고리의 다른 글
| [Cilium][3주차] Node & Pod 네트워크 통신 상세 - IPAM (4) | 2025.08.02 |
|---|---|
| [Cilium][2주차] 심화학습 과제! (3) | 2025.07.23 |
| [Cilium][2주차] Hubble을 통한 Cilium Traffic 가시성 확보 (3) | 2025.07.21 |
| [Cilium][1주차] 테스트 환경 구성과 Cilium 개념 정리 (0) | 2025.07.17 |
| [k8s] helm upgrade fail, remove api 조치 방안 (2) | 2023.02.05 |