
Summit 2일차의 날이 되었다. 1일차도 알찬 내용으로 가득했는데, 2일차는 기술부분의 세미나가 많아서 더욱 기대된다!
AWS Summit 기조연설
2일차 기조연설에서는 데브옵스에 대한 발표가 많았다.
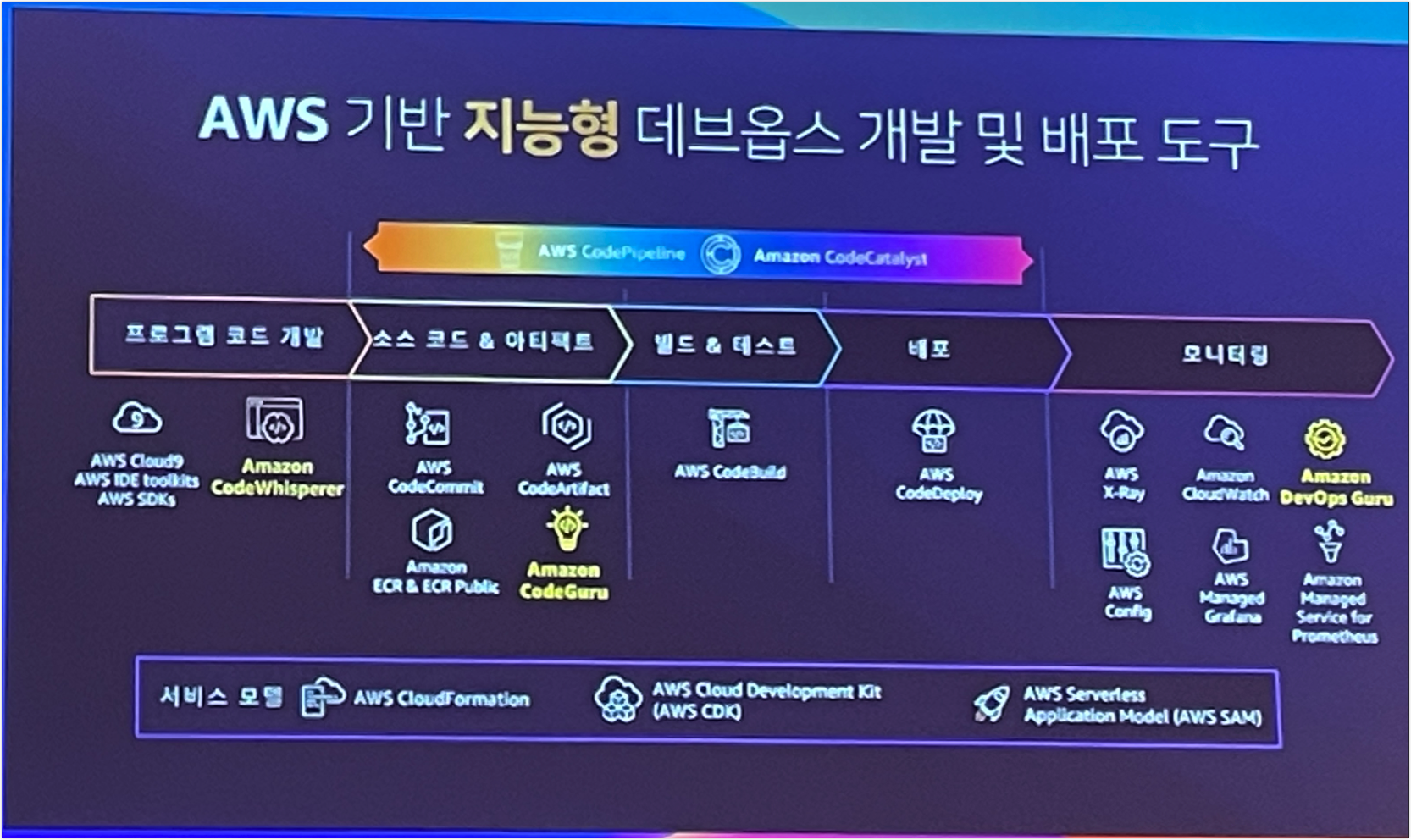
CodWhisper, Devops Guru 둘 다 처음들어보는 서비스인데 한번 이용해보면 좋을거 같다.
특히 Devops Guru는 EKS? 인프라에 대한 가이드를 알려준다고 하는데 적용 가능한 수준인지 궁금하다.
그리고 데브옵스에 대한 문화에 대한 이야기가 많았다. 공감했던 내용만 조금 추려서 말해보면 아래와 같다.
데브옵스팀에서는 모든 인프라 자원을 코드화하는것이 좋다.
- 코드화를 해야만 인프라 변경에 대한 이력관리가 가능하고 예측이 가능하며 이를 통제할 수 있다.
AWS Managed 서비스를 잘 이용하며 너무 편하다.
- AWS 서비스가 계속해서 만들어지고 새로워지는데, 기존 시스템을 마이그레이션하거나 PoC를 하면서 회사에 가장 부합하는 시스템을 만들고 인프라를 만들 수 있다.
- 특히 AWS Graviton 프로세스는 가격 대비 성능이 매우 탁월하다. 그렇기에 Graviton 사용이 가능하다면 사용하는것이 무조건적으로 이득이다.
AWS EKS 중요한건 꺾이지 않는 안정성
발표 주제 중에서 클러스터 업데이트 방안이 있었는데, 이번 Summit에서 가장 기대하고 있는 내용이다.
'23년 10월 EKS 업데이트를 해야하는데, 아무래도 업데이트가 서비스에 가장 영향이 크기에 타사에서는 어떻게 안정적으로 클러스터 업데이트를 하는지/서비스 안정성을 어떻게 보장하는지 궁금해서 가장 기대하는 세션이였다!!
앞부분에는 기본적인 AWS EKS에 대한 소개를 했다.
다 알고있겠지만, AWS EKS를 사용하면 컨트롤 플레인은 AWS에서 관리하며 데이터 플레인은 고객이 관리하게 된다.

그리고 AWS에서는 이를 책임 공유 모델이라고 한다.
직접 Kubernetes를 구축해서 사용하게 되면 etcd, api server 등 관리해야할 컴포넌트들이 많은데 EKS를 사용하여 관리 범위를 최소화하면서 동일한 서비스를 제공받는것이 중요한것 같다. 그 다음은 etcd, api server 등 각 컴포넌트들이 어떻게 고가용성을 보장하고 안정성을 보장하는지에 대해서 설명해주었는데, AWS를 믿기로 해서 따로 캡처는 하지 않았다ㅋㅋㅋㅋ

그 다음 App에 대한 자가복구를 위한 방법으로 헬스체크를 설명하였다. 헬스체크라고 해서 단순히 Request/Response 로 StatusCode만 확인하는 줄 알았는데 헬스체크에서도 많은 방법이 있었고, 이에 대해 알 수 있었다.
ReadnessProbe

핵심은 ReadnessProbe에서 헬스체크가 실패되면 엔드포인트에서 제외된다고는 점이다.
그리고 다시 헬스체크가 확인되면 엔드포인트에 추가하는 방식으로 동작한다. 즉, 헬스체크가 실패되더라도 Pod 재시작이 되지 않는다.
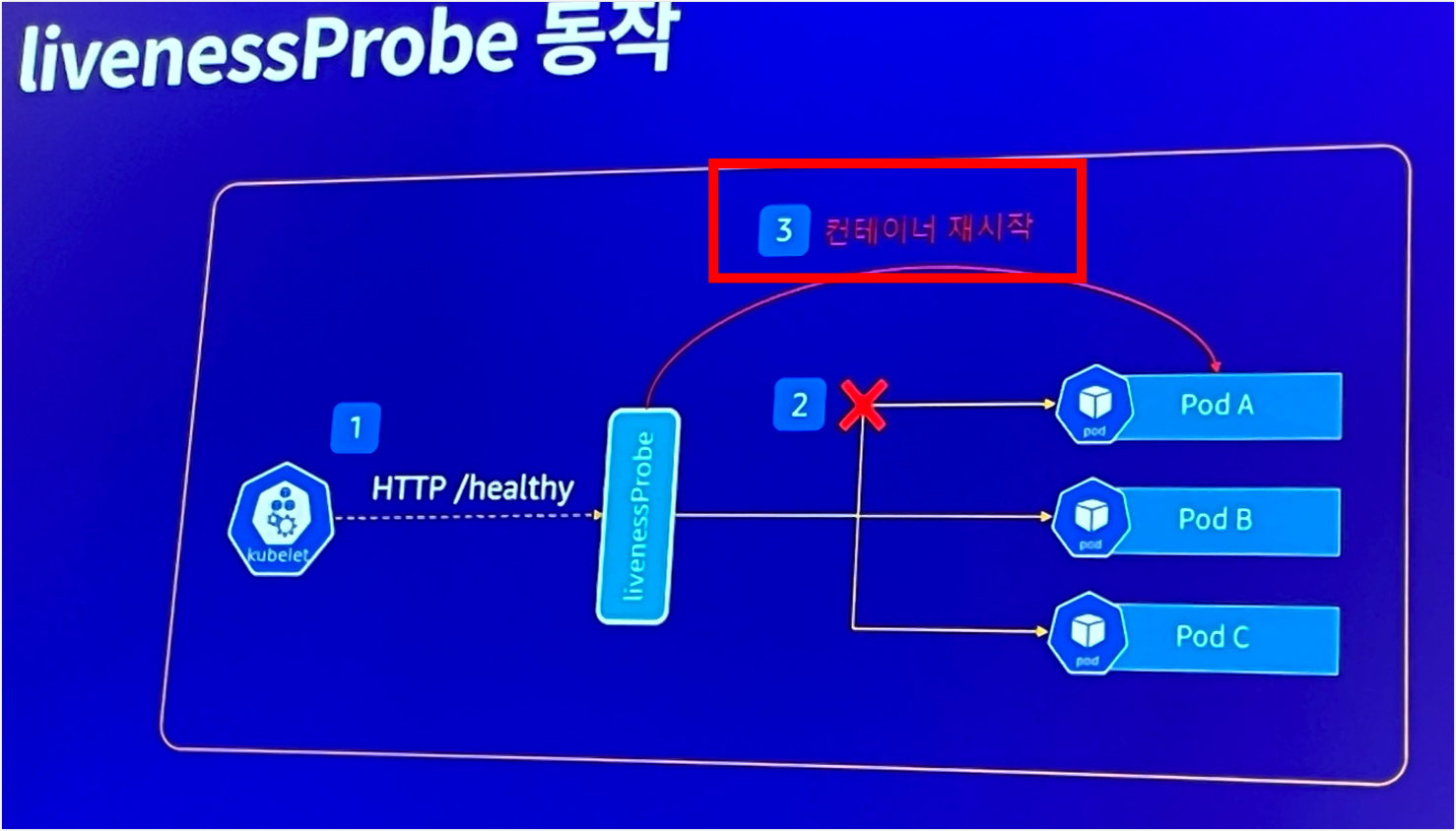
LivenessProbe
ReadnessProbe와 유사하지만 헬스체크를 실패했을때 컨테이너가 재시작된다는 점에서 다르다.
즉, 컨테이너가 재시작 건수가 많은 경우는 livenessprobe 실패가 많다는것을 뜻하고, 이를 App 상태가 정상적이지 않음을 뜻한다.
이외에도 PodAntiAffinity, TopologySpreadConstraints를 통해서 Pod을 각 Node에 분산하여 Node 장애 상황에 대해 피해를 최소화할 수 있는 방법을 설명하기도 하였다.
재직중인 회사에서는 AntiAffinity 등과 같은 전략을 전혀 사용하고 있지 않다. 이전부터 왜 이렇게 배포를 할까? 노드에 따라 분산을 하지 않아도 될까? 생각이 많았는데 이번 세션을 듣고 더욱 의구심이 많아졌다.
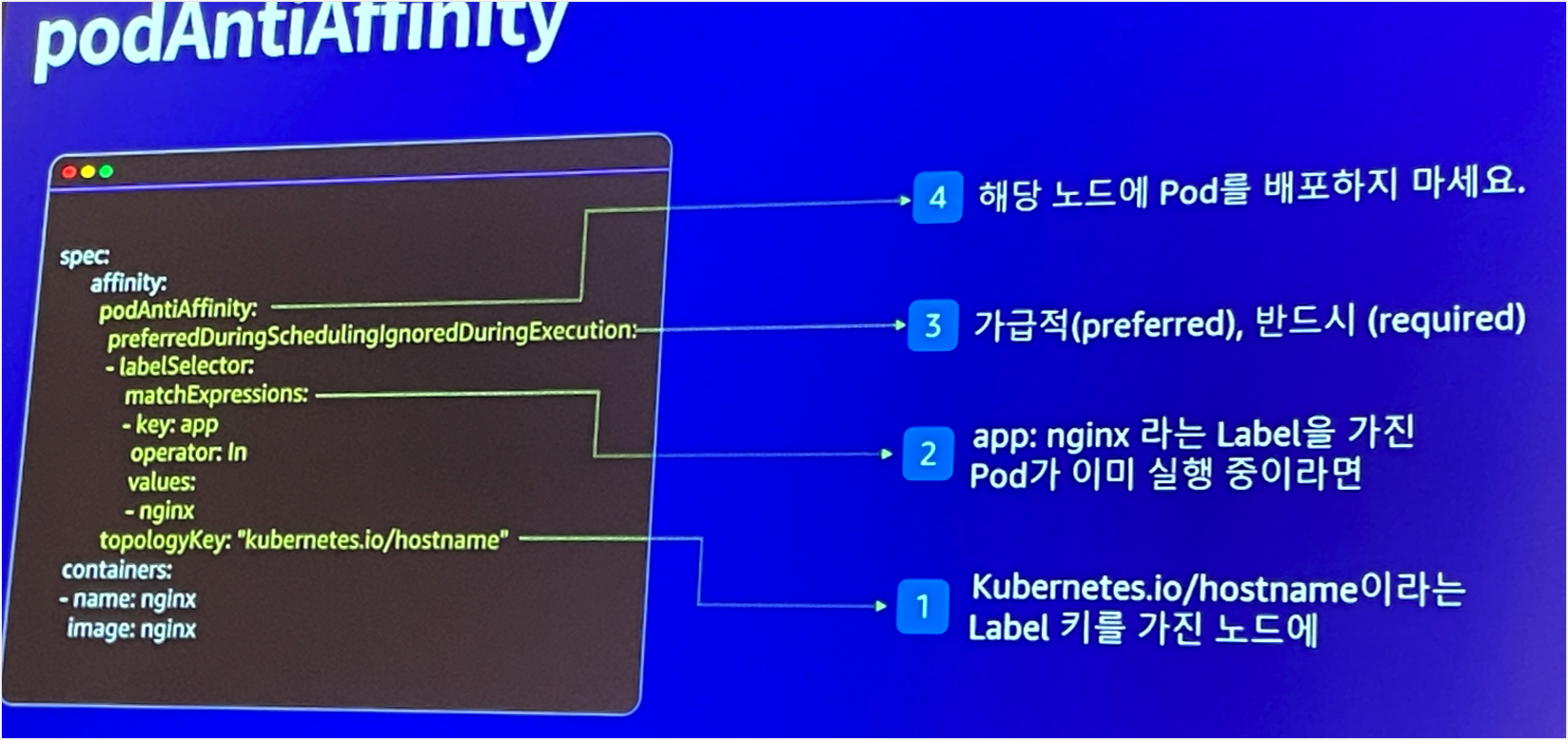

현재는 단일 Node에 서비스 Pod이 모두 배치될 수 있는 상황이고, 이런 경우 서비스 단절이 생길 수밖에 없다.
문제 상황 시 영향 범위를 최소화하는 관점에서 하반기에 꼭 고려해봐야하는 스펙이라고 생각한다.
Pod Eviction
Pod 중요도에 따라 Eviction이 되지 않도록 설정하는 것이 중요하다.
이때 적용되는 개념이 서비스 품질 클래스(QoS)이고 이는 Request/Limit 설정값에 따라서 달리 적용된다.

즉, Request = Limit으로 설정하면 Guaranteed 클래스로 취급되며 이는 가장 늦게 Eviction이 된다.
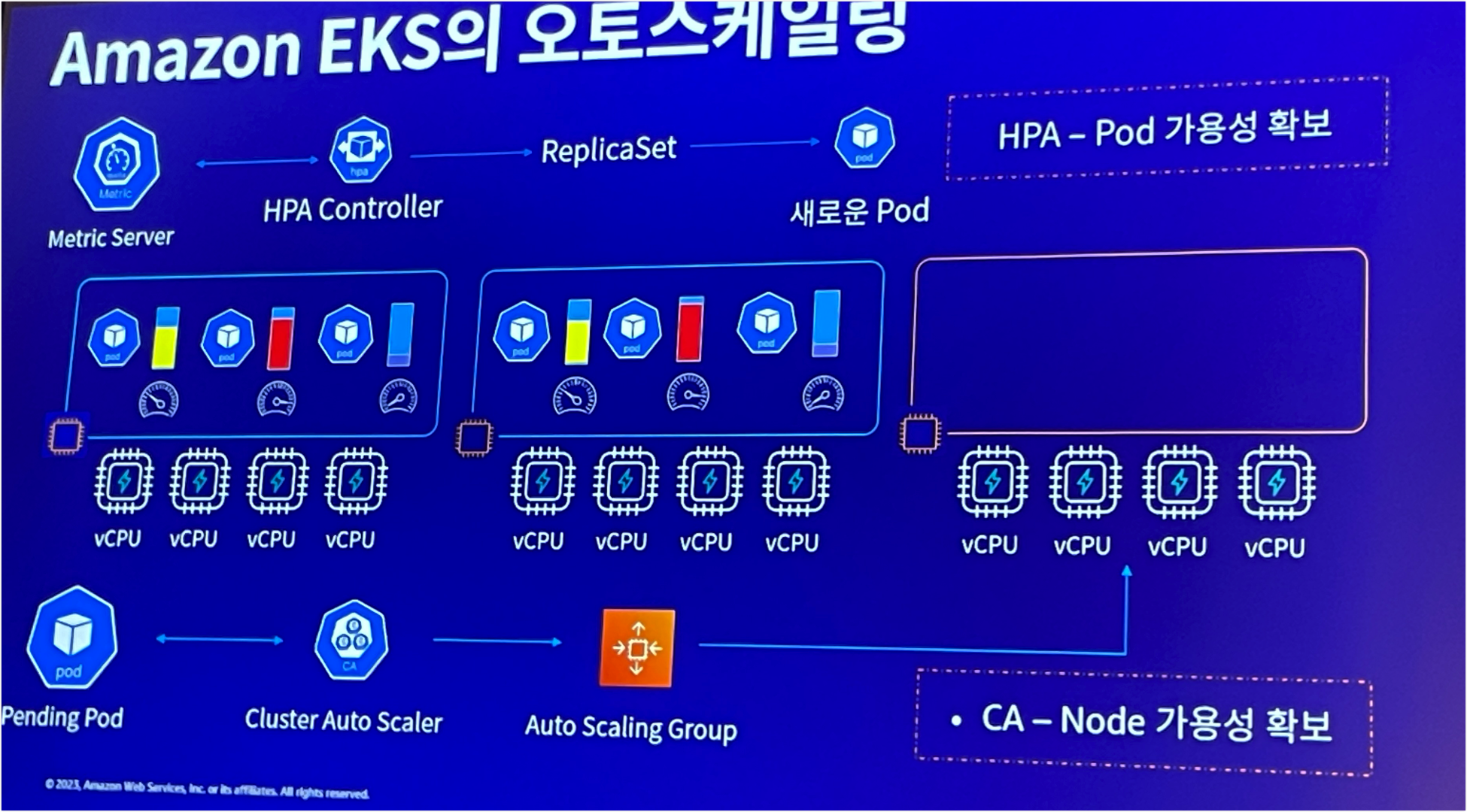
Pod 사용량이 늘어남에 따라서 Pod Scale-out이 일어나게 되고 이때 Node에 사용 가능한 자원이 없다면 현재 Pod을 Eviction 한다.
그리고 Eviction을 할 때는 긴 다운타임은 없겠으나, App에 따라 영향을 줄 수 있기 때문에 중요App은 가급적 Eviction으로 최소화하는것이 좋다.
현재 재직중인 회사에서는 Request != Limit을 달리 설정한다. 이것에 대한 답은 없는것 같다.
같이 설정하는게 정답일지, 다르게 설정하는 것이 정답일지... 각 회사의 상황과 대응 가능한 방법이나 모니터링 수단에 따라 다르게 하면 될것 같다. 뭐가 정답일까...
Cluster 업데이트 방안
곧 클러스터 업데이트를 앞두고 있는 입장에서 이번 세션에서 가장 듣고싶었던 내용이다.
업데이트 하기 가장 효율적인 방법은 무엇인지? 가장 안전한 방법은 무엇인지? 내가 생각하는 방향이 맞을까? 생각이 많았다.
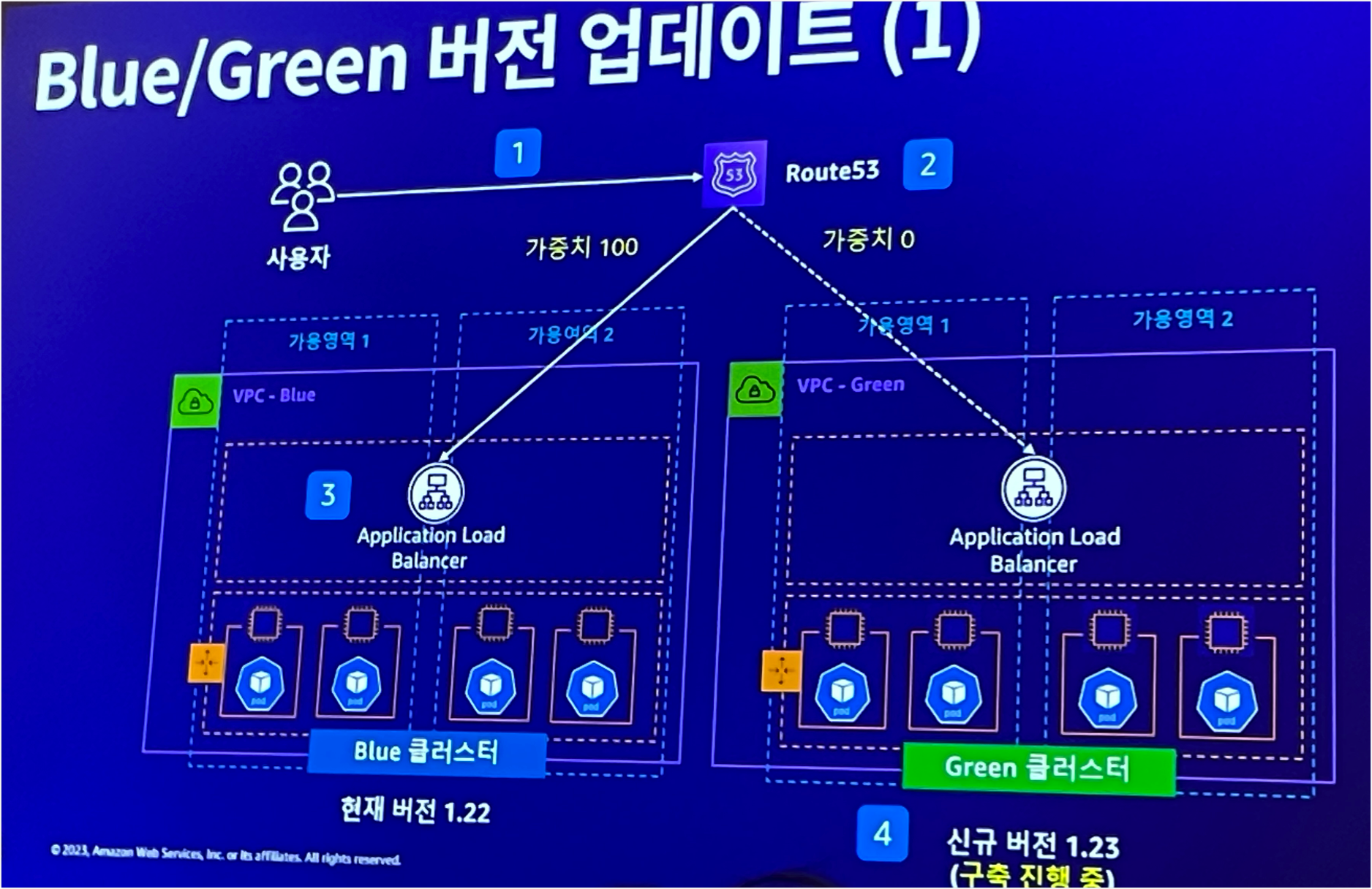
내용을 요약해보자면 아래와 같다.
- Argo CD 등의 CD Tool을 통해 블루/그린 클러스터를 생성한다.
- Route53에서 가중치 기반의 라우팅을 통해서 블루/그린의 클러스터 가중치를 달리한다. 일부만 그린 클러스터로 넘긴다.
- 순차적으로 그린 클러스터로 서비스 가중치를 넘기고, 100프로 다 넘기면 되면 블루 클러스터를 삭제한다.
Route53 가중치 기반 라우팅을 이용하는식으로 많이 업데이트를 하는것으로 알고있다.
In-Place 업데이트할 때 가장 부족한 부분이 1.롤백이 되지 않는다. 2.백업 방안을 별도로 수립해야한다. 3. 한 단계식 업데이트를 해야한다. 등의 여러가지 문제가 있는데, 블루/그린 업데이트 방안을 따르면 이를 해결할 수 있을것 같다.
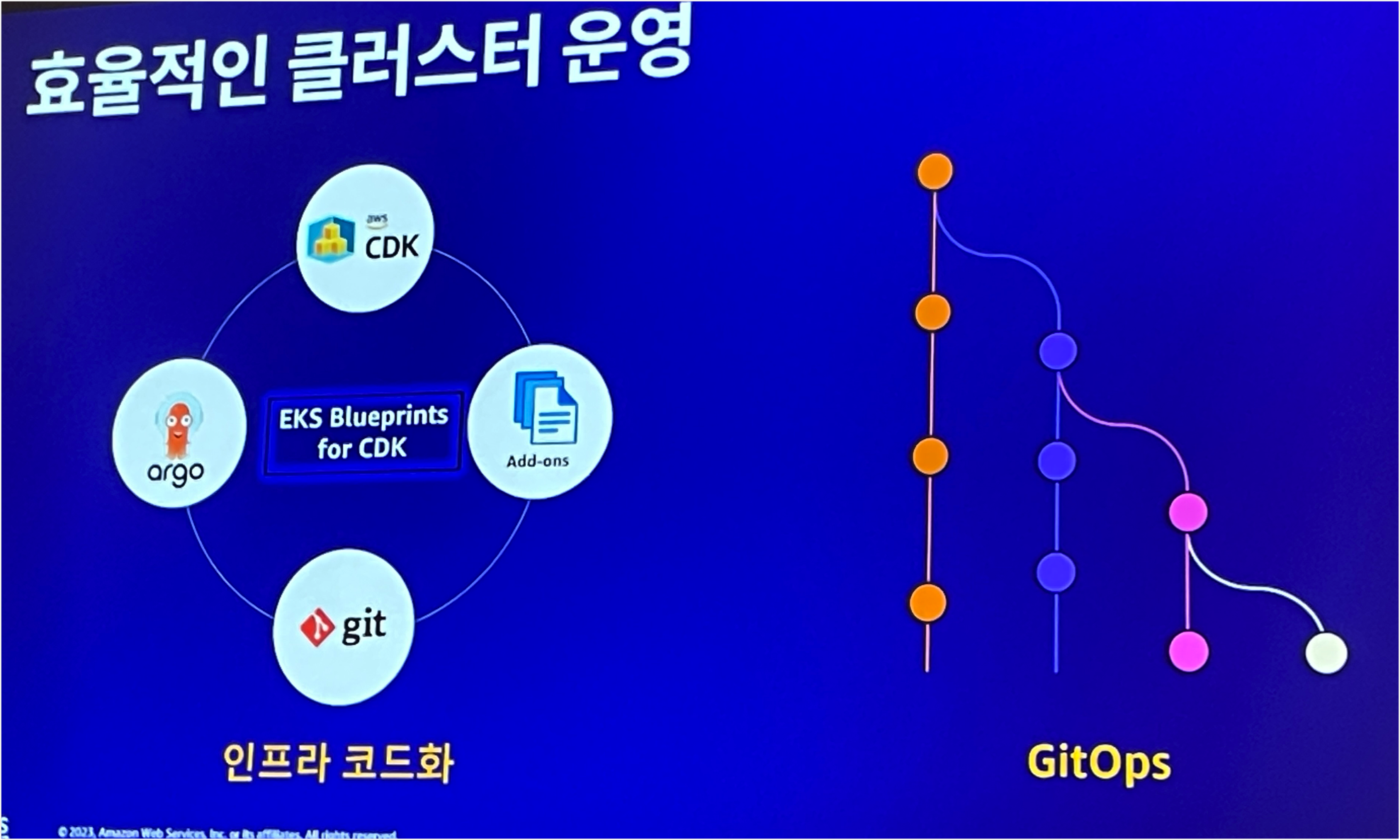
이를 위해서는 Argo CD와 같은 CD Tool이 있으면 좋을것 같고, 현재 CD Tool을 PoC를 하고 있으니까 이것까지 잘 고려해야겠다.
그래서 중요한것이 인프라 코드화 + Gitops이다.
인프라 코드화.. Terraform으로 진행하고 있는데 이게 실제 현행화하기에는 어려운점이 많은것 같다.
실제로 재직중인 회사에서 개발계 계정은 개발팀 등 다른팀에서 설정 변경을 하기도 하는데, 이를 매번 Terraform으로 업데이트하기 어려움이 많다. 운영계정 일부만 Terraform으로 관리하고 있으나 이것도 적은 인원으로 IaC를 구현하려니 많은 어려운점이 있다.
AWS Summit을 참여해서 여러가지 정보와 사례를 많이 볼 수 있어서 좋았다.
내가 생각한 방향이 맞는지 확인할 수 있는 계기가 되기도 했고, 내가 몰랐던 지식을 새롭게 알 수 있는 기회가 되기도 했다.
중요한것은 Summit을 통해 듣고/배웠던 내용을 실천하는것일것 같다.
지금은 회사에서 여러가지 업무와 상황들로 인해 새로운 것을 하기 어려운 상황인데. 시간이 되면 이번 Summit에서 알게된것을 꼭 다 해보고싶다!!
끝!!
'일상 이모저모' 카테고리의 다른 글
| [AWS][DNA] AWS DNA 5기 회고록 [2/2] - 해커톤 (2) | 2023.09.18 |
|---|---|
| [AWS][DNA] AWS DNA 5기 회고록 [1/2] - 교육 (0) | 2023.09.18 |
| [Seminar] AWS Summit 2023 Seoul 1일차 [2/2] (0) | 2023.05.06 |
| [Seminar] AWS Summit 2023 Seoul 1일차 [1/2] (0) | 2023.05.06 |
| [AWSKRUG] AWS Security Hands-on Meetup(12/17) (0) | 2022.12.18 |