
3일차, 4일차, 5일차는 해커톤이 진행되었다.
실제 재직중인 회사에서 겪고 있는 문제점을 AWS DNA 5기에서 배웠던 서비스를 토대로 문제점을 식별하고, 개선하고 발표하는거였다!
해커톤 주제 선정
가장 먼저 해야할일이 해커톤 주제 선정이였다. 필자는 AWS DNA를 신청한 사유가 명확했다.
실제로 현재 재직중인 회사에서 아래2가지 문제점이 있었고 이를 AWS DNA를 통해서 개선하고 싶었다.
- 서비스 로그 수집 파이프라인의 문제점
- 실시간 스트림 데이터에 대한 BI 제공
해커톤 진행
서비스 로그 수집 파이프라인 문제점 개선
기존에는 아래와 같이 서비스 로그를 수집하였다. Logging Operator 오픈소스를 사용하였고, 각 EKS 노드에는 Fluentbit이 배포되어있다. 그리고 Fluentbit -> Flientd -> S3로 최종 서비스 로그가 저장되었다.
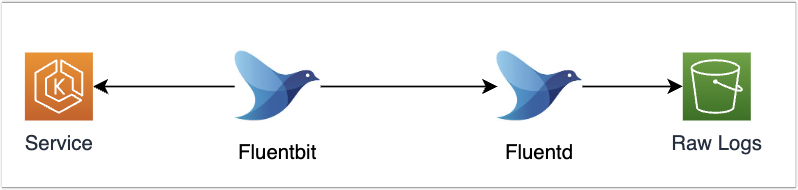
그런데 이렇게 하면 문제가 발생한다.
- Fluentbit에서는 메모리에 로그를 저장하고, 일정시간 기준으로 Fluentd로 전송한다.
- 그럼 이때 과도한 로그가 유입되는 경우 메모리 이상의 로그가 쌓이게 될 수 있다. 그리고 로그 유실이 발생한다.
- 실제로 재직중인 회사에서는 MSK 구조의 istio을 사용하는데 이런 경우 로그가 과도하게 발생할 수 있다.
- 그렇다고 Pod 메모리 사용량을 늘릴 수 있으나, 빈번하지도 않은 경우를 대비해서 늘리는것도 비용 효율적이지 않다.
- Fluentbit에서 그럼 일정시간을 매우 작은 시간으로 설정할 수도 있으나 이렇게 되면 S3에 Object 개수가 매우 많아진다.
- 그리고 Object 개수가 많아지면 Spark에서 처리하기 힘들다 ㅜㅜ
그래서 생각한것이 Fluentd에서 실시간으로 보내되, Object 개수가 많아지는것을 방지하기 위해서 Kinesis를 도입하는것이다.
Fluentd에서는 Kinesis Data Stream으로 실시간으로 데이터를 전송한다. 그리고 Kinesis Firehose에서 KDS를 구독한다.
KDS는 Queue 시스템이기 때문에 데이터 누락을 보장할 수 있고, Kinesis Firehose에서는 일정시간 또는 일정크기에 만족하는 경우 S3에 전송하여 S3에 Object 개수가 많아지는 것을 방지했다.
그리고 OpenSearch를 또 다른 Tarkget으로 설정해서 S3로 전송되는 로우 데이터에 대한 가시성을 확보하였다.
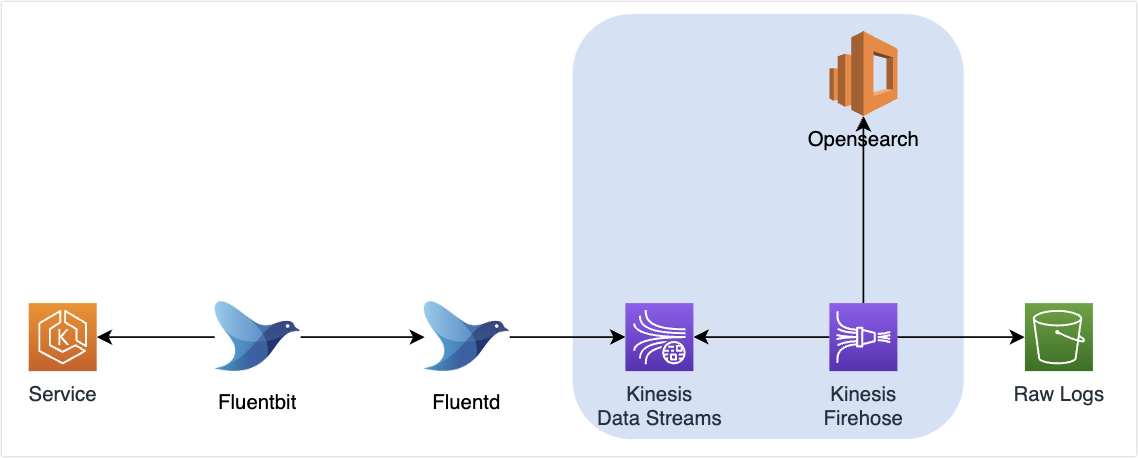
대부분의 회사?에서 서비스 로그는 이런 형태와 유사하게 중간에 Queue를 두고, S3 또는 Data Lake에 적재하는 것으로 알고있다.
필자도 Queue를 중간에 둬야지 둬야지.. 생각만 하고 있다가 이번에 AWS DNA에서 교육을 받으면서 딱 하면 좋을것 같다고 생각해서 도입을 하였다. 지금보면 크게 어렵지 않았다. Stream을 만들고, 해당 Stream을 구독하는 Firehose를 만들고 Target만 정하면 됬다. 이전에는 왜 안했을까ㅎㅎ 생각이 든다.
실시간 스트림 데이터에 대한 BI 제공
기존에는 Raw Logs에 저장된 데이터를 기준으로 EMR Serverless에서 일 2회 Batch job을 진행하여 사용자에게 제공했다.
그렇기 때문에 사용자는 전일자 데이터만 볼 수 있었고, 사용자 동시접속자 수/이벤트 참여율 등의 실시간 데이터는 확인할 수 없었다.
- 확인할 수 없었다기 보다, 데이터 엔지니어분이 DB에 접속해서 쿼리하고.. 그 결과를 다시 사용자한테 전달해주는 수동 방식
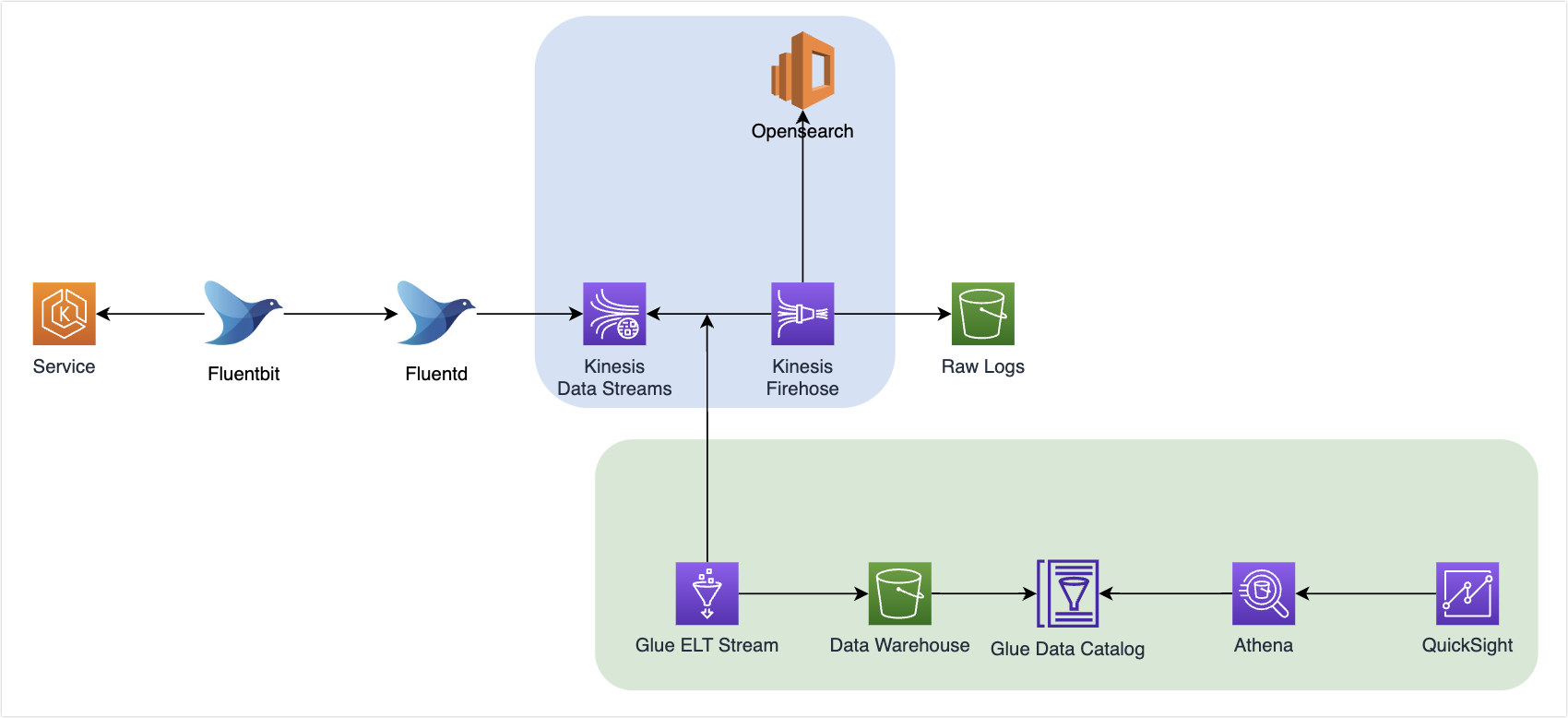
위 서비스 로그 수집 파이프라인 문제점 개선에서 KDS를 도입하였다. 그리고 이번에는 KDS에서 수집된 데이터를 다시 한번 Glue ETL에서 구독해서 Data Warehouse를 적재하기로 했다.
Glue ETL에서는 KDS에 적재된 데이터를 받아서 Spark 코드를 통해 미리 정의한 메트릭을 특정 시간(1분) 기준으로 데이터를 뽑을 수 있었다.
- Spark 코드는 데이터 엔지니어분이 구현하였으며, 그 내용은 구독하는 정보를 1분 주기로 Sum을 해서 Data Warehouse에 저장하는 것이였다.
- 그리고 Checkpoint를 지정해서 다음 1분 후에는, 해당 Checkpoint를 참조해서 데이터 가공 시점을 정하는 방식이였다.
위와 같이 하게 되면 Data Warehouse에는 1분 주기로 수집된 데이터가 적재된다.(실시간은 아니고 준실시간)
그리고 QuickSight에서는 Athena를 통해 Data Warehouse에 적재된 데이터를 읽을 수 있으므로 QuickSight에서는 실시간 데이터와 배치성 데이터를 같이 보여줄 수 있었다.
AWS DNA를 끝으로
위 주제로 해커톤을 진행하였으나, 수상까지는 하지 못했다.(3등까지 상품이 있었는데, 좋은 상품이였다.)

재직중인 회사에서 진행하다보니 Cross Account에 대한 권한 설정과 VPC Peering에 대한 여러가지 제약사항이 있었고, 해커톤 발표 전날까지도 ETL 설정을 하고 권한에 많은 시간을 쏟았었다.
비록 수상까지는 못했지만, 금번 AWS DNA 프로그램을 통해 평소 생소했던 서비스에 대해 알게되었고 문제점을 개선할 수 있는 좋은 시간이였다.

이 글을 AWS 분들이 보실지는 잘 모르겠으나, AWS 분들에게 감사의 마음을 전하고싶다.
서비스 제공 업자 - 고객의 관계가 아니라, 문제를 겪고 있는 사람과 그 문제를 해결해줄 수 있는 사람의 관계로 회사 이익을 떠나서 매우 적극적으로 필자의 문제점에 대해 고민해주는 모습이 좋았다.
밤 늦게까지 질문하는 것에도 잘 설명해주셨고, 다소 간단했한 문의에 대해서도 성심성의껏 자료를 찾아주고 하신점이 매우 좋았다.
(사진은 문제가 될 시, 삭제하도록 하겠습니다.)
아쉬웠던점은
한가지 아쉬웠던점은 다른 회사와의 네트워킹이 조금 부족했던거 같다.
물론 네트워킹이라고 하면.. 스스로 해야겠지만 아무래도 회사 사람들과 같이 팀을 이뤄 진행하고 프로그램도 짧게 진행하다보니 다른 회사 사람과 이야기할 수 있는 시간과 기회가 조금 부족했던거 같았다.
사실 AWS DNA 프로그램의 핵심은 다른 회사의 네트워킹이라고 들었고, 이번에 네트워크킹을 많이 기대하고 갔는데 없어서 좀 아쉬웠다.
아쉬운점이 한가지 있었지만, 아쉬운점을 상회할만큼 많은 장점이 있는 프로그램이였다.
AWS를 사용하시는분이라면 꼭 추천하고 싶은 프로그램이다. 그리고 앞으로도 매년 진행했으면 좋겠다.
아래는 이모티콘으로 다 가렸지만, 교육만 한게 아니라 AWS분들과 즐겁게 한 음식 사진을 끝으로 게시물을 마무리합니다~

이 게시물을 보실지 모르겠지만, AWS 분들 고생많으셨습니다. 감사합니다.
'일상 이모저모' 카테고리의 다른 글
| [회고] 남들 다 하는 2023년 회고, 나도 하자 (2) | 2024.01.01 |
|---|---|
| [AWS][DNA] DNA 5기 참여 그 이후 (0) | 2023.10.15 |
| [AWS][DNA] AWS DNA 5기 회고록 [1/2] - 교육 (0) | 2023.09.18 |
| [Seminar] AWS Summit 2023 Seoul 2일차 (0) | 2023.05.06 |
| [Seminar] AWS Summit 2023 Seoul 1일차 [2/2] (0) | 2023.05.06 |