
[Cilium][3주차] Node & Pod 끼리의 네트워크 통신 상세 - 1
이제 어느덧 스터디 3주차에 접어들었다.이번주는 집안일이 있어서, 스터디 온라인 시간에 직접 참여하지는 못했고 녹화영상으로 참여를 했다.2주차까지는 Cilium 그리고 Hubble에 대해서 설치하고
dobby-isfree.tistory.com
이전 게시물에서 실습 환경을 조성하고, IPAM 특히나 kubernetes -> cluster-pool로 전환하는 과정과
DicrectRouting에 대해서 알아보았다. 이번에는 Routring에 대한 상세한 과정과 DNS 호출 과정에 대해서 알아본다.
Routing
지금까지 Kubernetes를 운영하면서, 크게 신경쓰지 않았던 부분이다.
당연히 kube-proxy에서 알아서(?) 잘 해주겠지하는 마음이 있었다.
그래서 NodeIP로 NAT되거나, 캡슐화 과정 이에 따른 네트워크 지연과 CPU 오버헤드에 대해서도 고민을 하지 않았다.
하지만 Cilium을 사용하는 사람들은 성능 최적화, 특히나 네트워크 지연에 대한 많은 관심이 있기 떄문에
이번 기회에 나도 관심을 가져보려고 한다.
Overlay
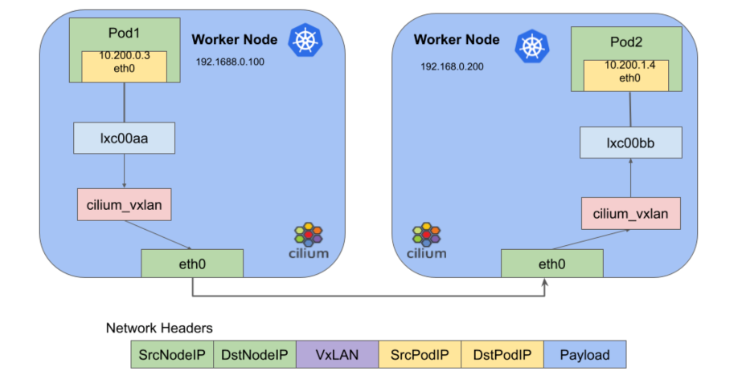
가장 일반적으로 사용하는 방식일것 같다.
쉽게 말하면 Node 외부와 통신할떄는 NodeIP로 캡슐화(=헤더를 추가해서, 터널을 만들어서) 통신을 하는것이다.
그래서 어떤 구간에서 tcpdump를 확인하는지에 대해서 SrcIP가 달라지는것이다.
[ Pod 1 (10.200.0.3) ]
↓
Cilium VXLAN Encapsulation]
↓
[ Node 1 eth0 (192.168.0.100) ] -> VXLAN UDP Packet
↓
[ Node 2 eth0 ] ← src=192.168.0.100 : Node1로 NAT되어 도착한다.
↓
[Cilium VXLAN Decapsulation] : 이 과정에서 Node1로 NAT 되었던것이 풀리고, 실제 Pod IP로 변환된다.
↓
[ Pod 2 (10.200.1.4) ] ← src=10.200.0.3
Overlay 모드에는 여러 장점이 있다.
1. 네트워크에서는 podIP를 신경쓸 필요가 없다.
- Node 외부와 통신할 떄는 NodeIP로 NAT되서 통신하기 때문에 Node IP 대역으로만 라우팅을 하면 된다.
2. 네트워크 토폴로지에 크게 영향받지 않고, TGW 그리고 AWS와 같은 Cloud와 연계도 쉽다.
3. 노드 라우팅 테이블이 단순하다.
- 모든 podCIDR에 대해서는 cilium VXLAN 인터페이스로 가는 설정만 하면 된다.
그러나 단점도 있다.
1. 가장 큰 단점은 네트워크 지연이 발생할 수 있다.
- 캡슐화, 디캡슐화 과정에서 CPU 오버헤드가 발생하고 이에 따른 시간이 필요하다.
2. MTU 오버헤드가 발생한다.
- 일반적으로 MTU 1500 byte일 때 캡슐화를 위해 50 byte를 사용한다. 그러면 최대 1450 byte만 사용 가능하다.
- 물론 점보 프레임같은 큰 MTU 값을 사용하면 이에 대한 영향은 낮아지겠지만 불필요한 헤더가 생기는것이다.
DirectRoutung(=Native-Routing)

반면 directRouting에서는 위 그림과 같이 NodeIP로 NAT되지 않고 podIP로 바로 통신이 이뤄진다.
그러기 위해서는 각 노드의 podCIDR별로 라우팅테이블이 설정되어 있어야 한다.
- 하지만, 모든 노드에 대해서 개별적으로 고정 라우팅테이블을 설정하는것은 힘들고
- 다른 네트워크 대역의 노드에 대해서는 설정이 불가능하기 때문에 일반적으로는 BGP 등의 추가 시스템 구성이 필요하다.
[ Pod 1 (10.200.0.3) ]
↓
[Node 1 eth0 (192.168.0.100) -> 커널 라우팅 테이블, 라우팅: 10.200.1.0/24 → via 192.168.0.101 (Node 2)
↓
[ Node 2 eth0 (192.168.0.101) ] ← src=10.200.0.3
↓
[ Pod 2 (10.200.1.4) ] ← src=10.200.0.3
그래서 실습 환경에서 통신테스트를 해보면, 서로 다른 노드임에도 pod RealIP로 직접 통신을 하고 있고,
각 노드에 라우팅테이블을 보면 podCIDR별로 라우팅테이블 설정이 되어 있다.
하지만 캡슐화 과정이 없기 때문에 단계가 아주 많이 축소된것을 볼 수 있다.
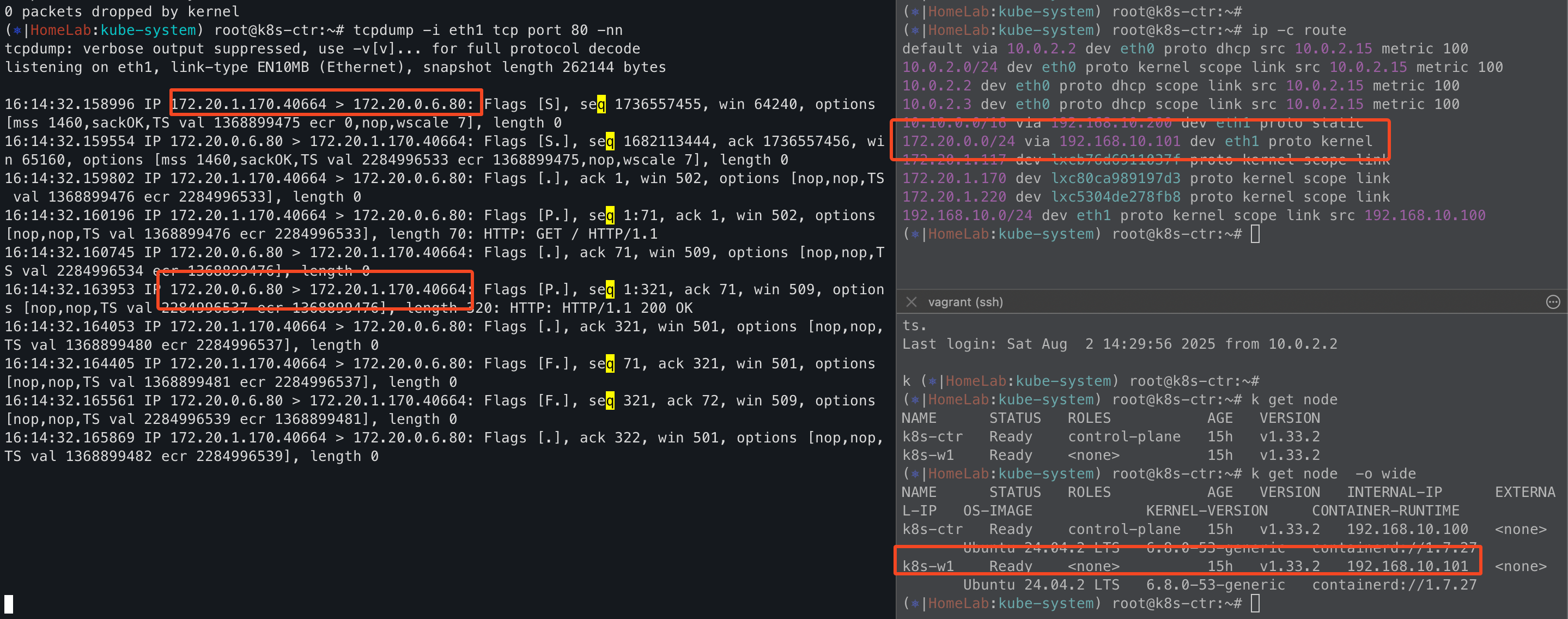
Masquerading
흔히 Pod에서 Node 외부와 통신할떄는 Node IP로 NAT된다. 이것은 SNAT 또는 Masquerading했다. 라고 표현한다.
- 쉽게 말하면 SNAT 하는것이다.
cilium status를 보면 Masquerading 설정이 되어 있고, podCIDR 인 172.20.0.0/16에 대해서 적용하는것으로 설정되어 있다.
- 여기서 헷갈리면 안되는것은 172.20.0.0/16에 대해서 Masquerading을 "할 수 있다"라는 의미이다.
- 해당 IP CIDR에 대해서 SNAT 하겠다는 의미가 아니다.
^C(⎈|HomeLab:kube-system) root@k8s-ctr:~kubectl exec -it -n kube-system ds/cilium -c cilium-agent -- cilium status | grep Masqueradingng
Masquerading: BPF [eth0, eth1] 172.20.0.0/16 [IPv4: Enabled, IPv6: Disabled]
---
(⎈|HomeLab:kube-system) root@k8s-ctr:~# k get cm cilium-config -oyaml |grep ipv4-native-routing-cidr
ipv4-native-routing-cidr: 172.20.0.0/16ipv4-native-routing-cidr이 설정되어 있기 때문에 해당 IP CIDR에 대해서는 SNAT를 하지 않는다.
그래서 정리하면 출발지가 172.20.0.0/16이면서 & ipv4-native-routing-cidr로 지정한 대역이 아닌 경우 SNAT 하는것이다.
통신 테스트
테스트를 해보면 www.naver.com은 native-routing-cidr가 아니기 때문에 podIP가 아니라 nodeIP로 SNAT되었다.
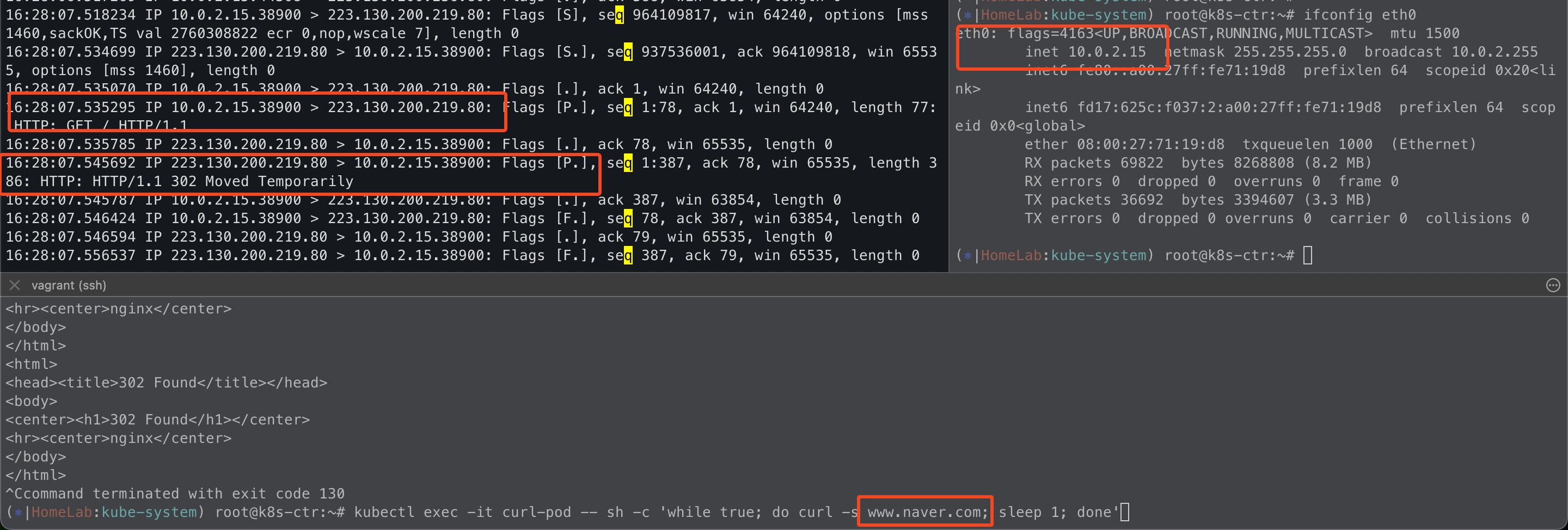
또한, 실습 환경에서 구현한것과 같이 k8s-ctr -> router로 통신 테스트를 해도
router는 native-routing-cidr가 아니기 때문에 k8s-ctr 노드IP로 SNAT되서 통신을 하는 모습이다.


IPMasquerading 전/후 비교
ipMasqAgent를 적용하기 전에는 ipv4NativeRoutingCIDR에 없는 IP대역이므로 SNAT되어 NodeIP를 사용한다.
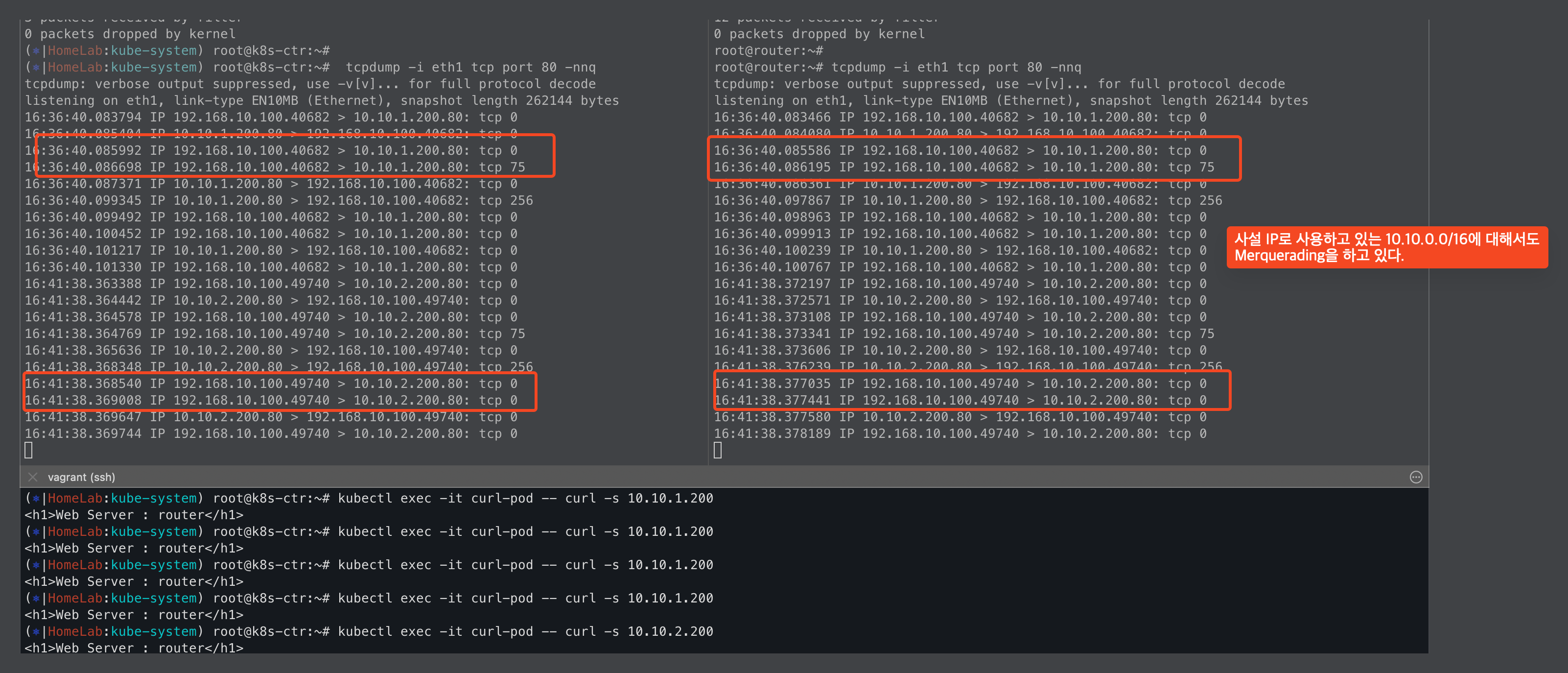
그리고 ipMasqAgent를 배포해서 사용하면, ipv4NativeRoutingCIDR과 동일하게 podIP로 직접 통신하는것을 볼 수 있다.
helm upgrade cilium cilium/cilium --namespace kube-system --reuse-values \
--set ipMasqAgent.enabled=true --set ipMasqAgent.config.nonMasqueradeCIDRs='{10.10.1.0/24,10.10.2.0/24}' --version 1.17.6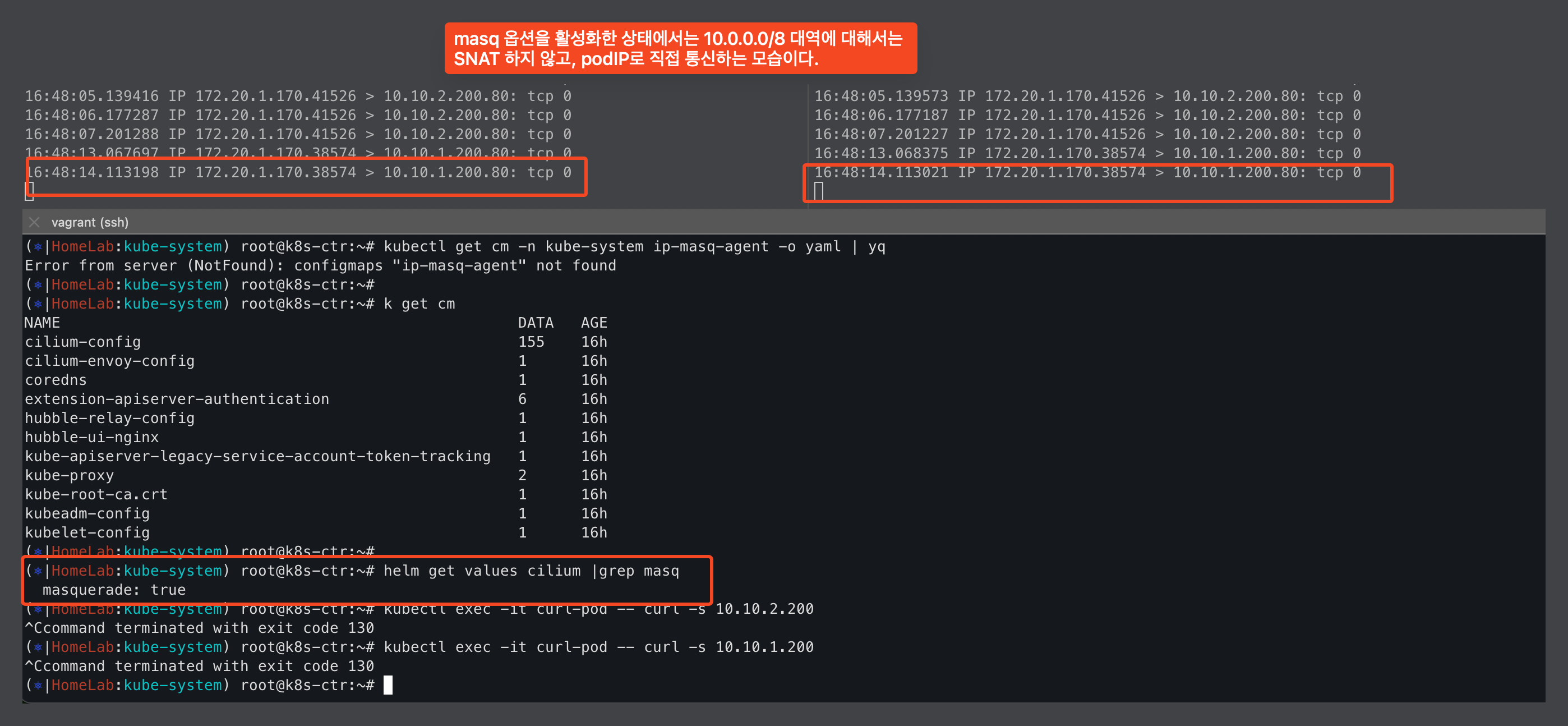
그러면 1가지 의문점이 생긴다. 그렇다면 애초에 ipv4NativeRoutingCIDR에 여러 ipCIDR을 넣으면 되는거 아닌가?
결론부터 말하면 불가능하다. ipv4NativeRoutingCIDR에는 ipCIDR를 1개만 넣을 수 있다.
그러면 다시 의문점.. 그럼 ipv4NativeRoutingCIDR를 사용안해도 되는것이 아닌가?
결론은 아래와 같이 여러 IP대역을 넣기 위해 사용할 수 있고, 실 사례도 많이 있다.
--set bpf.masquerade=false \
--set ipMasqAgent.enabled=true \
--set ipMasqAgent.config.nonMasqueradeCIDRs='{172.20.0.0/16,10.10.0.0/16,192.168.0.0/16}'
얼핏보면 ipv4NativeRoutingCIDR 설정과 ipMasqAgent 설정는 같은 목적이지만, 적용 모드와 성능면에서 차이가 있다.
정답은 없는것 같다. 각 회사의 상황과 초점을 두고있는 범주에 맞춰서 적용하면 될것 같다.
| 설정 | 역할 | SNAT 주체 | ipCIDR | 성능 | 적용 모드 |
| bpf.masquerade | pod -> 외부 SNAT 예외 |
cilium | 단일 IP 대역 | 고성능 | Only DirectRouting |
| ipMasqAgent | iptables | 다수 IP 대역 | 오버헤드 발생 | DirectRouting + Overlay 모드 |
CoreDNS + NodeLocalDNS
coreDNS는 필수로 사용하고, 대규모의 Kuberenetes를 운영하는 곳이라면 node-local-dns를 많이 사용하고 있을것 같다.
CoreDNS

coreDNS의 구조는 간단하다. 각 노드의 resolve.conf를 보면 kube-dns의 svc IP를 가지고 있다.
그리고 kube-dns는 coreDNS pod을 endpoint를 가지므로, 결국에는 coreDNS를 호출한다.
(⎈|HomeLab:kube-system) root@k8s-ctr:~# kubectl exec -it curl-pod -- cat /etc/resolv.conf
search kube-system.svc.cluster.local svc.cluster.local cluster.local
nameserver 10.96.0.10
options ndots:5
(⎈|HomeLab:kube-system) root@k8s-ctr:~# cat /var/lib/kubelet/config.yaml | grep cluster -A1
clusterDNS:
- 10.96.0.10
clusterDomain: cluster.local
containerRuntimeEndpoint: ""
(⎈|HomeLab:kube-system) root@k8s-ctr:~# k get svc |grep kube-dns
kube-dns ClusterIP 10.96.0.10 <none> 53/UDP,53/TCP,9153/TCP 17h그리고 coreDNS에서 참조하고 있는 configMap을 보면 모든 DNS에 대해서 허용하고 있다.
없는 도메인 정보에 대해서는 다시 /etc/resolv.conf를 참고하고 30초의 Cache를 가지도록 되어 있다.
- 예시에는 errors, log, loop, reload 등과 같은 Plugin을 사용하고 있지만 다양한 Plugin이 있다.
(⎈|HomeLab:kube-system) root@k8s-ctr:~# kc describe cm -n kube-system coredns
Name: coredns
Namespace: kube-system
Labels: <none>
Annotations: <none>
Data
====
Corefile:
----
.:53 {
errors
health {
lameduck 5s
}
ready
kubernetes cluster.local in-addr.arpa ip6.arpa {
pods insecure
fallthrough in-addr.arpa ip6.arpa
ttl 30
}
prometheus :9153
forward . /etc/resolv.conf {
max_concurrent 1000
}
cache 30 {
disable success cluster.local
disable denial cluster.local
}
log
loop
reload
loadbalance
}실제로 Pod에서 svc 이름으로 nslookup을 해보면 CoreDNS에서는 webpod의 svc IP를 반환한다.

기본적으로 CoreDNS는 순서대로 FQDN 도메인을 호출하여 Kuberenetes 도메인인지 확인 한 다음에
매칭되는게 없다면 외부 DNS에 질의하여 IP를 찾는 방식이다.
그래서 google.com으로 nslookup을 해보면 처음부터 외부 DNS에 호출하지 않고 kubernetes svc부터 검색한다.

이러한 과정은 Hubble을 통해서 보면, 더욱 직관적으로 알수 있다.
curl pod에서 nslookup google.com으로 1번만 했을뿐인데, 실제로 패킷은 다수 발생하였다.
그리고 kube-dns 즉, CoreDNS가 외부 DNS에 질의하여 최종 IP를 받아와서 전달하는 과정을 보여준다.
- Hubble이 있어서 직관적으로 볼 수 있으니깐 참 좋은것 같다.
- 그리고 기본적으로 :53은 Hide 처리가 되어 있기 때문에 우측 상단 탭에서 Hide를 해제해야한다.

보는것과 같이 모든 DNS 쿼리는 CoreDNS에서 담당하게 된다. 그렇기 때문에 CoreDNS는 부하는 심할 수 밖에 없다.
물론 ttl, cache와 같이 부하를 완화하기 위한 조치가 있다.
하지만 결과적으로는 CoreDNS 부하는 생길 수밖에 없고 네트워크 지연이나 홉도 간과할 수 없다.
그래서 각 노드에 CoreDNS의 역할을 하는 시스템을 배포하는 목적으로 NodeLocalDNS가 나왔다.
NodeLocalDNS
NodeLocalDNS는 이름에서 알 수 있는것처럼 각 노드에 Daemonset 형태로 배포되어 Local Cache처럼 동작한다.
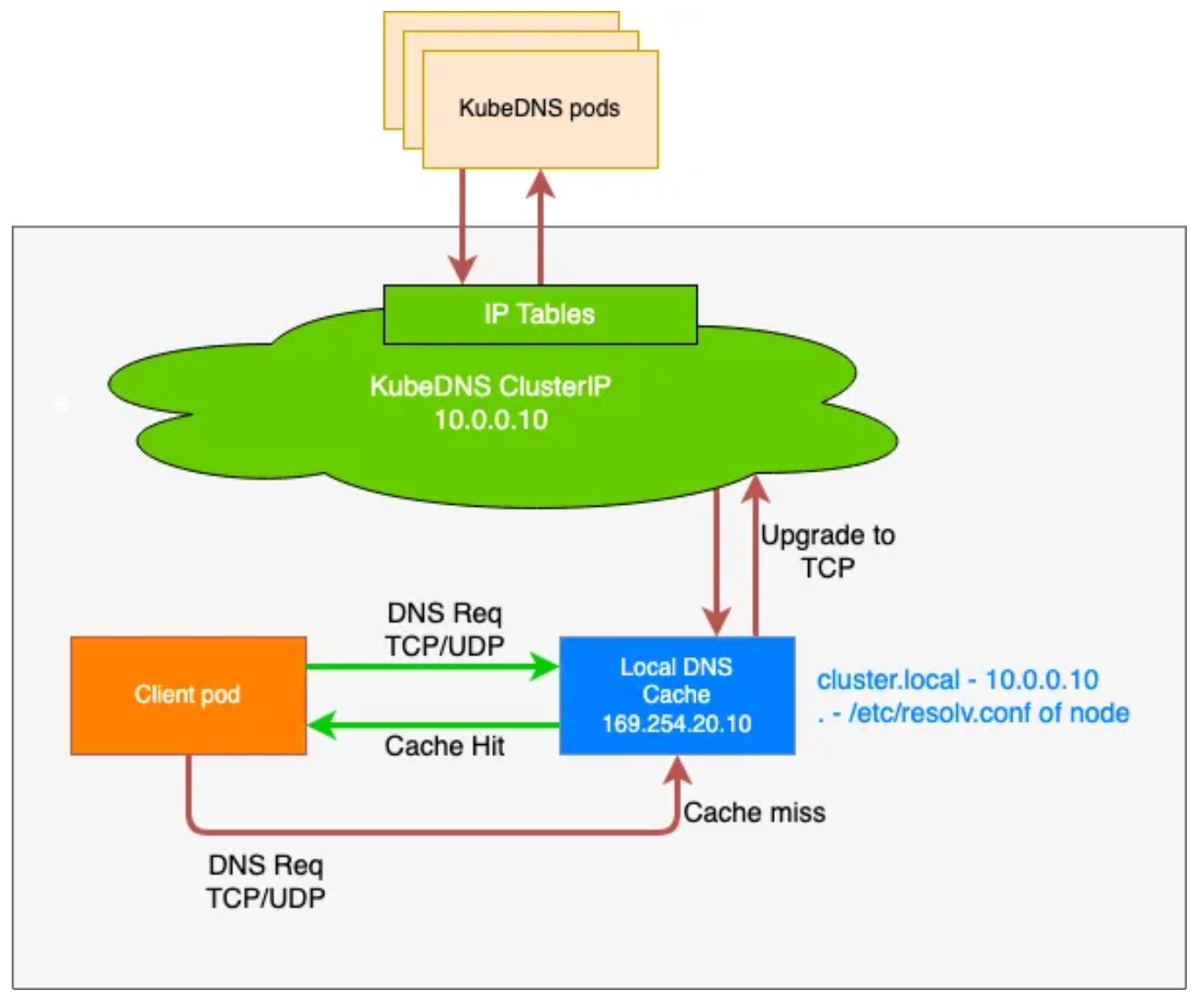
기본적으로 클라이언트에서는 CoreDNS를 호출하지 않지 않는다.
무조건 NodeLocalDNS만 호출한다. Proxy의 역할을 하여 CoreDNS의 부하를 경감시킨다.
그리고 필요한 경우에 대해서만 NodeLocalDNS가 CoreDNS에 호출하는 방식이다.
이뿐만 아니라 CoreDNS만 사용할때는 아래 2가지의 큰 위험이 있다.
- CoreDNS를 사용하면 CoreDNS svc IP를 호출하고 이를 다시 CoreDNS pod IP로 DNAT 해야한다.
- 그리고 이러한 연결과정을 conntrack에 기록하게 되는데, 대량의 DNS 호출이면 conntrack entry를 모두 소진할 위험도 있다.
하지만 NodeLocalDNS는 Local IP로 바로 통신하게 되므로 DNAT, conntrack에 문제에 대해서 비교적 자유롭다.
설치하는 방법은 kubernetes에서 공식적으로 제공해주고 있는 yaml을 사용하면 된다.
다만 공식 yaml에서 일부 변수에 대한 치환이 필요하기 때문에 sed로 적절한 값을 치환한다.
wget https://github.com/kubernetes/kubernetes/raw/master/cluster/addons/dns/nodelocaldns/nodelocaldns.yaml
# kubedns 는 coredns 서비스의 ClusterIP를 변수 지정
kubedns=`kubectl get svc kube-dns -n kube-system -o jsonpath={.spec.clusterIP}`
domain='cluster.local' ## default 값
localdns='169.254.20.10' ## default 값
echo $kubedns $domain $localdns
sed -i "s/__PILLAR__LOCAL__DNS__/$localdns/g; s/__PILLAR__DNS__DOMAIN__/$domain/g; s/__PILLAR__DNS__SERVER__/$kubedns/g" nodelocaldns.yaml최종적으로 공식 yaml과 비교해보면 현재 클러스터의 IP에 맞춰서 적절한 값이 들어간 모습이다.

배포 하고 나면, node-local-dns가 daemonset으로 생기고, 마찬가지로 전용 Corefile이 생겨난다.
Corefile은 CoreDNS보다 더 세분화되어 있고, 기본적으로 node-local-dns와 CoreDNS가 dule-binding되어 있다.
- dule-binding이 되어 있는 이유는 node-local-dns에 없는 정보는 상위의 CoreDNS에 질의하기 위함이다.

하지만 실제로 테스트를 해보면 node-local-dns로 호출을 해야할것 같지만, 여전히 CoreDNS를 사용한다.
resolve.conf에 CoreDNS svc IP를 가지고 있기 때문에 어찌보면 당연한 결과이다.
그리고 resolve.conf를 node-local-dns IP인 169.254.20.10으로 변경하면 node-local-dns를 사용할것이다.

하지만 우리는 이런 방법을 원하지 않고 cilium을 사용하면 트래픽에 대한 리다이렉트를 지원할 수 있다.
cilium에서는 이런 상황일 때 localRedirectPolicy, lrp를 지원하고 있다.
이를 통해서 특정 svc로 나가는 트래픽을 원하는 백엔드 또는 svc로 리다이렉션해서 트래픽 조정을 할 수 있다.
사용하기 위해서는 cilium helm values를 추가한다.
helm upgrade cilium cilium/cilium --namespace kube-system --reuse-values \
--set localRedirectPolicy=true --version 1.17.6
# cilium-operator는 반드시 재시작을 해줘야하고,
# cilium은 일정 시작이 지나면 reload 되기 때문에 굳이 안해도 된다.
kubectl rollout restart deploy cilium-operator -n kube-system
kubectl rollout restart ds cilium -n kube-system그리고 cilium에서 제공하고 있는 node-local-dns yaml을 사용해서 재배포를 하면 된다.
재배포를 하면 차이점은 node-local-dns configmap에서 bind가 0.0.0.0으로 나오지만, 크게 중요하지 않다.
wget https://raw.githubusercontent.com/cilium/cilium/1.17.6/examples/kubernetes-local-redirect/node-local-dns.yaml
kubedns=$(kubectl get svc kube-dns -n kube-system -o jsonpath={.spec.clusterIP})
sed -i "s/__PILLAR__DNS__SERVER__/$kubedns/g;" node-local-dns.yaml
kubectl apply -f node-local-dns.yaml그리고 가장 중요한 lrp도 배포한다. 배포한 lrp를 해석하면 다음과 같다.
kube-system/kube-dns로 가는 트래픽을 k8s-app: node-local-dns로 리다이렉트한다. 그리고 이때 udp, tcp:53을 사용한다.
쉽게 말하면 DNAT를 cilium을 통해서 대신한다고 볼 수 있다.
wget https://raw.githubusercontent.com/cilium/cilium/1.17.6/examples/kubernetes-local-redirect/node-local-dns-lrp.yaml
cat node-local-dns-lrp.yaml | yq
apiVersion: "cilium.io/v2"
kind: CiliumLocalRedirectPolicy
metadata:
name: "nodelocaldns"
namespace: kube-system
spec:
redirectFrontend:
serviceMatcher:
serviceName: kube-dns
namespace: kube-system
redirectBackend:
localEndpointSelector:
matchLabels:
k8s-app: node-local-dns
toPorts:
- port: "53"
name: dns
protocol: UDP
- port: "53"
name: dns-tcp
protocol: TCP
cilium-dbg를 통해서 lrp list를 봤을 때 iptabels DNAT와 유사하게 되어 있다.

그리고 내부 또는 외부 도메인에 대해서 호출을 하면, 먼저 node-local-dns를 호출해서 확인하고
없는 결과에 대해서 CoreDNS, 외부 DNS를 호출하는 모습을 볼 수 있다.

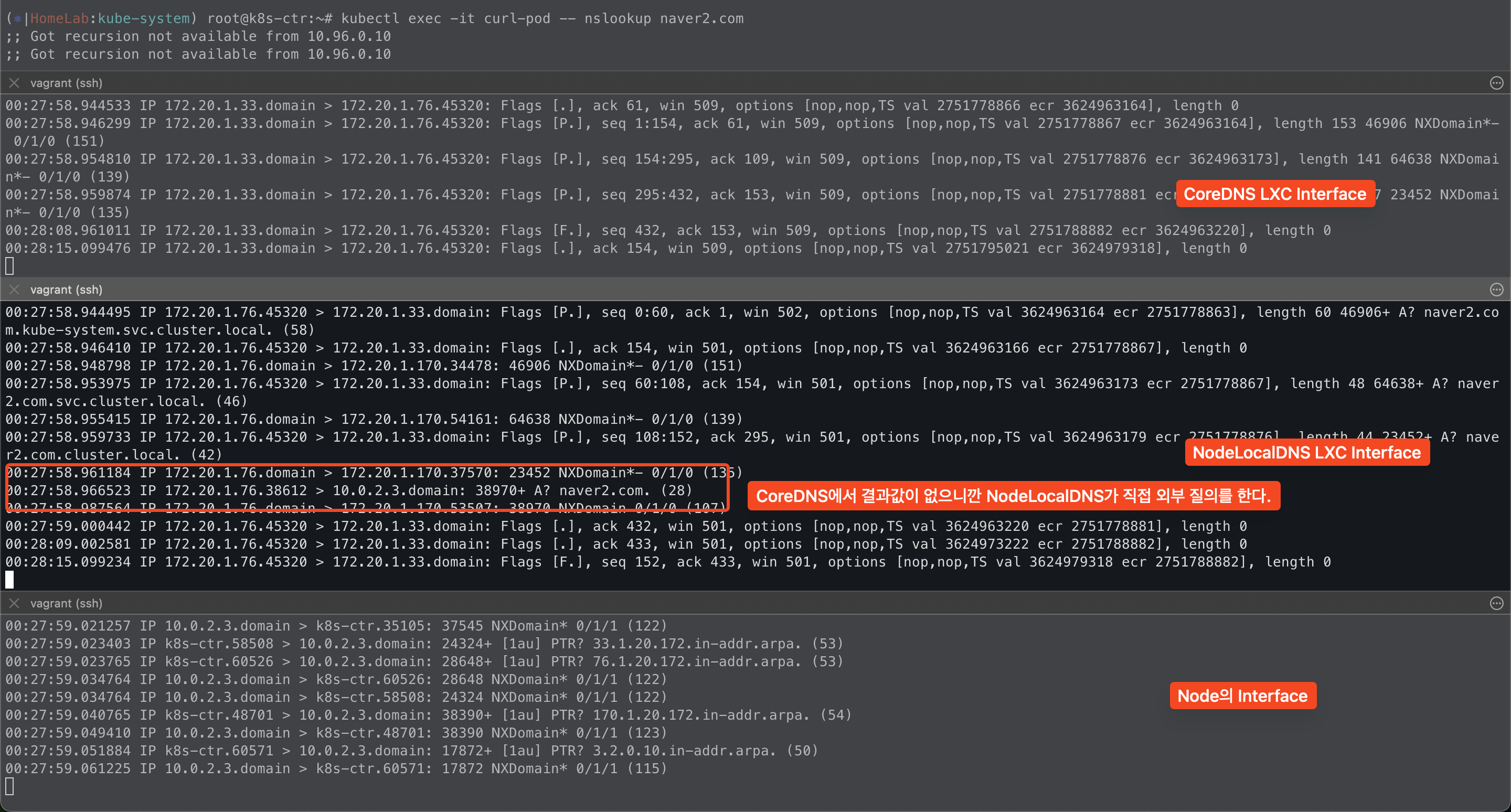
한가지 여기에서 특이한점은 hubble에서는 node-local-dns 그리고 CoreDNS에서 외부 DNS 질의를 하는것처럼 표현되어 있다.

하지만, 실제로 각 Pod이 가지고 있는 lxc 인터페이스에 대해서 tcpdump를 해보면
외부 도메인에 대해서 질의를 할 때 node-local-dns에서 외부 도메인에 대해서 직접 질의하는 것을 볼 수 있다.
- 왜지? 이론상으로는 없는 도메인에 대해서는 CoreDNS가 외부 DNS에 질의하는것으로 알고있는데? 왜지?
- 왤까...
node-local-dns를 사용하고 있지만, 이를 지원하기 위해서 resolve.conf를 변경하지 않고 lrp를 사용하는게 인상깊었다.
그리고 dns에서 위해서 lrp를 사용했지만, 이뿐만 아니라 내가 원하는 형태로 트래픽을 제어할 수 있다는것이 좋았다.
- 회사에서는 lrp 객체를 배포하지 않았기 때문에 아마.. resolve.conf에 local IP를 넣어놨을것 같다.
그리고 한가지 좀 이해가 안되는건, 외부 도메인에 대해서 CoreDNS가 질의하지 않고 node-local-dns가 직접 외부 질의를 한다.
hubble 그리고 lxc 인터페이스를 tcpdump를 해보면 그렇다. 뭔가 내가 알고있는 이론과 맞지가 않다.
왤까??? 뭘 잘못 설정한것일까? 이건 좀 더 찾아봐야겠다.

'기술 토론장 > [K8s] Kubernetes' 카테고리의 다른 글
| [Cilium][4주차] Node & Pod 네트워크 통신, Service External-IP 활용 (1) | 2025.08.10 |
|---|---|
| [Cilium][4주차] Node & Pod 네트워크 통신, Native vs VXLAN (6) | 2025.08.09 |
| [Cilium][3주차] Node & Pod 네트워크 통신 상세 - IPAM (4) | 2025.08.02 |
| [Cilium][2주차] 심화학습 과제! (3) | 2025.07.23 |
| [Cilium][2주차] Prometheus/Grafana을 통한 Cilium 가시성 확보 (0) | 2025.07.22 |