이제 7주차이다. 이번 주차의 내용은 성능 퍼포먼스이다!!! 딱 맞는 주제이다.
최근 회사에서 클러스터 Control plane 노드가 다운되는 일이 빈번하게 발생하고 있다..
현상은 kube-apiserver에 요청이 많아서 발생하고 있는데, 어떻게 하면 요청을 효과적으로 처리할 수 있을지?
클러스터 규모를 어떻게 산정해야 할지 고민이 많았는데 이번 주차 내용이랑 딱 맞는 내용이다.
실습 환경 구성(not cilium)
이번 주차에서도 kind를 이용해서 실습 환경을 구성한다.
그리고 성능 측정이 주 내용이기 때문에 control plane 노드 1대로 구성한다.
k8s 버전은 1.33을 사용한다. 1.33 버전에서 lIst를 처리하는 방식이 개선되어 많은 성능 개선이 되었다고 한다.
1.33 이전에는 기존에는 etcd로부터 읽어온 정보를 모두 메모리에 올려서 응답에 대한 구조체를 만들어서 전달했다.
그렇기 때문에 응답이 모두 전달될때까지 메모리에 데이터를 들고있고, 동시에 요청하는 경우 oom이 발생하였다.
하지만 1.33 이후 버전에서는 list로 전달받은 객체 정보를 한개씩 구조체로 만들고, 바로 응답으로 전달하고 메모리에서 해제한다.
그렇기 때문에 메모리에 장시간 떠있는 데이터가 줄어들게 되고 그만큼 oom이 발생할 확률이 줄었다.
kind create cluster --name myk8s --image kindest/node:v1.33.2 --config - <<EOF
kind: Cluster
apiVersion: kind.x-k8s.io/v1alpha4
nodes:
- role: control-plane
extraPortMappings:
- containerPort: 30000
hostPort: 30000
- containerPort: 30001
hostPort: 30001
- containerPort: 30002
hostPort: 30002
- containerPort: 30003
hostPort: 30003
kubeadmConfigPatches: # Prometheus Target connection refused bind-address 설정
- |
kind: ClusterConfiguration
controllerManager:
extraArgs:
bind-address: 0.0.0.0
etcd:
local:
extraArgs:
listen-metrics-urls: http://0.0.0.0:2381
scheduler:
extraArgs:
bind-address: 0.0.0.0
- |
kind: KubeProxyConfiguration
metricsBindAddress: 0.0.0.0
EOF지표 측정(prometheus) 도구 설치
지표 측정을 위해서 prometheus stack을 설치하고, 대시보드 id를 import해서 사용한다.
- k8s dashboard id : 15661, kube-apiserver dashboard id : 12006
--- metrics server install ---
helm repo add metrics-server https://kubernetes-sigs.github.io/metrics-server/
helm upgrade --install metrics-server metrics-server/metrics-server --set 'args[0]=--kubelet-insecure-tls' -n kube-system
--- prometheus stack install ---
helm install kube-prometheus-stack prometheus-community/kube-prometheus-stack --version 75.15.1 \
-f monitor-values.yaml --create-namespace --namespace monitoring
--- monitor-vales.yaml ---
prometheus:
prometheusSpec:
scrapeInterval: "15s"
evaluationInterval: "15s"
service:
type: NodePort
nodePort: 30001
grafana:
defaultDashboardsTimezone: Asia/Seoul
adminPassword: prom-operator
service:
type: NodePort
nodePort: 30002
alertmanager:
enabled: false
defaultRules:
create: false
prometheus-windows-exporter:
prometheus:
monitor:
enabled: false그러면 지금 kube-ops-view를 통해서 pod lifecycle에 대해서 시각적으로 확인할 수 있고,
promethues stack을 통해서 부하에 대한 지표 측정이 가능한 상황이다.

부하 테스트(kube-burner) 도구 설치
pod 생성, 삭제를 시각적으로 보기 위해 kube-ops-view를 설치하는데, 생각보다 시각적으로 표현이 잘된다.
kube-ops-view
Kubernetes Operational View - read-only system dashboard for multiple K8s clusters
codeberg.org
helm repo add geek-cookbook https://geek-cookbook.github.io/charts/
helm install kube-ops-view geek-cookbook/kube-ops-view --version 1.2.2 --set service.main.type=NodePort,service.main.ports.http.nodePort=30003 --set env.TZ="Asia/Seoul" --namespace kube-system
kube-burner을 이용해서 부하 테스트를 진행한다.
qps 조정도 가능하고 쉽게 pod, configmap, secrets 등의 객체도 yaml로 정의하고 생성할 수 있어서 편한 도구인것 같다.
- 회사에서는 부하 테스트를 할 때 kubectl proxy로 kube-apiserver를 직접 호출하는 방식으로 했었는데.. 역시 도구가 좋다.
--- 로컬에서 호출하기 위해서 proxy 설정 ---
kubectl proxy --port=8081 &
--- api-server 1건 호출 ---
curl "localhost:8080/api/v1/pods?limit=1000" > /dev/null
--- 부하 테스트를 위해서 10개의 클라이언트로 총 1,000건의 api-server 요청 ---
xargs -I % -P 10 curl -s -o /dev/null :127.0.0.1:8081/api/v1/pods:limit=5000" << (printf '%s\n' {1..1000})
Kube-burner
What is Kube-burner Kube-burner is a Kubernetes performance and scale test orchestration toolset. It provides multi-faceted functionality, the most important of which are summarized below. Create, delete, read, and patch Kubernetes resources at scale. Prom
kube-burner.github.io
git clone https://github.com/kube-burner/kube-burner.git
cd kube-burner
curl -LO https://github.com/kube-burner/kube-burner/releases/download/v1.17.3/kube-burner-V1.17.3-darwin-arm64.tar.gz # mac M
tar -xvf kube-burner-V1.17.3-darwin-arm64.tar.gz
sudo cp kube-burner /usr/local/bin
사용하는 방법은 간단하게 설명하면 먼저 k8s 객체 yaml이 있어야 하고, 그리고 kube-burner yaml이 있어야한다.
kube-burner yaml에서는 k8s 객체 yaml을 몇번 호출할지, qps를 어떻게 설정해서 생성할지를 정의한다.
kube-apiserver 부하 테스트 w.kube-burner
시나리오 1. 단일 deployment 배포
--- kube-burner yaml ---
global:
measurements:
- name: none
jobs:
- name: create-deployments
jobType: create
jobIterations: 1 # 반복 횟수
qps: 1 # 초당 처리할 요청 개수
burst: 1 # 순간적으로 처리할 요청 개수, 약간 qps와 비슷한 개념이다.
namespace: kube-burner-test
namespaceLabels: {kube-burner-job: delete-me}
waitWhenFinished: true # 처리가 다 될때까지 cli를 대기한다.
verifyObjects: false
preLoadImages: true # 부하 테스트 이전에 노드에 컨테이너 이미지를 다운 받는다.
preLoadPeriod: 30s # 리소스 생성 후, 일정 시간이 지난 다음에 지표를 측정한다.
objects:
- objectTemplate: s1-deployment.yaml # 어떤 객체로 테스트할지를 설정한다.
replicas: 1
--- k8s deployment 객체 ---
apiVersion: apps/v1
kind: Deployment
metadata:
name: deployment-{{ .Iteration}}-{{.Replica}}
labels:
app: test-{{ .Iteration }}-{{.Replica}}
kube-burner-job: delete-me
spec:
replicas: 1
selector:
matchLabels:
app: test-{{ .Iteration}}-{{.Replica}}
template:
metadata:
labels:
app: test-{{ .Iteration}}-{{.Replica}}
spec:
containers:
- name: nginx
image: nginx:alpine
ports:
- containerPort: 80사용하는 방법 또한 매우 간단하다. kube-burnel cli 커맨드만 실행하면 된다.
kube-burner init -c s1-config.yaml --log-level debug
시나리오 1은 아주 작은, 단순한 deployment 생성이기 때문에 grafana에서 확인하는 지표 변화량이 크지 않다.
삭제는 labels 기준으로 삭제를 할 수 있고, 생성할 때 kube-burner-job key로 label을 추가했기 때문에 이를 활용한다.
- 삭제이기 때문에 jobType이 delete 이다.

테스트를 해보면 중요한것 jobIterations, qps, burst 그리고 replias이다.
jobiterations * replicas 만큼 요청이 발생하고, qps, burst 값을 기반으로 동시 요청이 발생한다.
burst가 높으면 높을수록 동시 요청이 많아지고, qps가 높으며 높을수록 빠르게 처리가 된다.
시나리오 2.노드 최대 pod 개수 배포
아래와 같이 수정해서 kube-burner 커맨드를 실행한다.
jobs:
- name: create-deployments
jobType: create
jobIterations: 100
qps: 300
burst: 300
'''
--- 부하 테스트 시작 ---
kube-burner init -c s1-config.yaml --log-level debug이때 그라파나에서 배포를 확인해보면 pod을 생성하기 때문에 api-server request total이 늘어나고
일시적으로 cpu, memory도 급증하는 모습을 보인다. 심지어 중간에는 메트릭 지표 수집이 끊어지기도 했다.

노드 최대 pod 만큼 배포했기 때문에 문제가 생겼다기 보다, 동시에 api-server에 요청이 발생해서 문제가 된것이다.
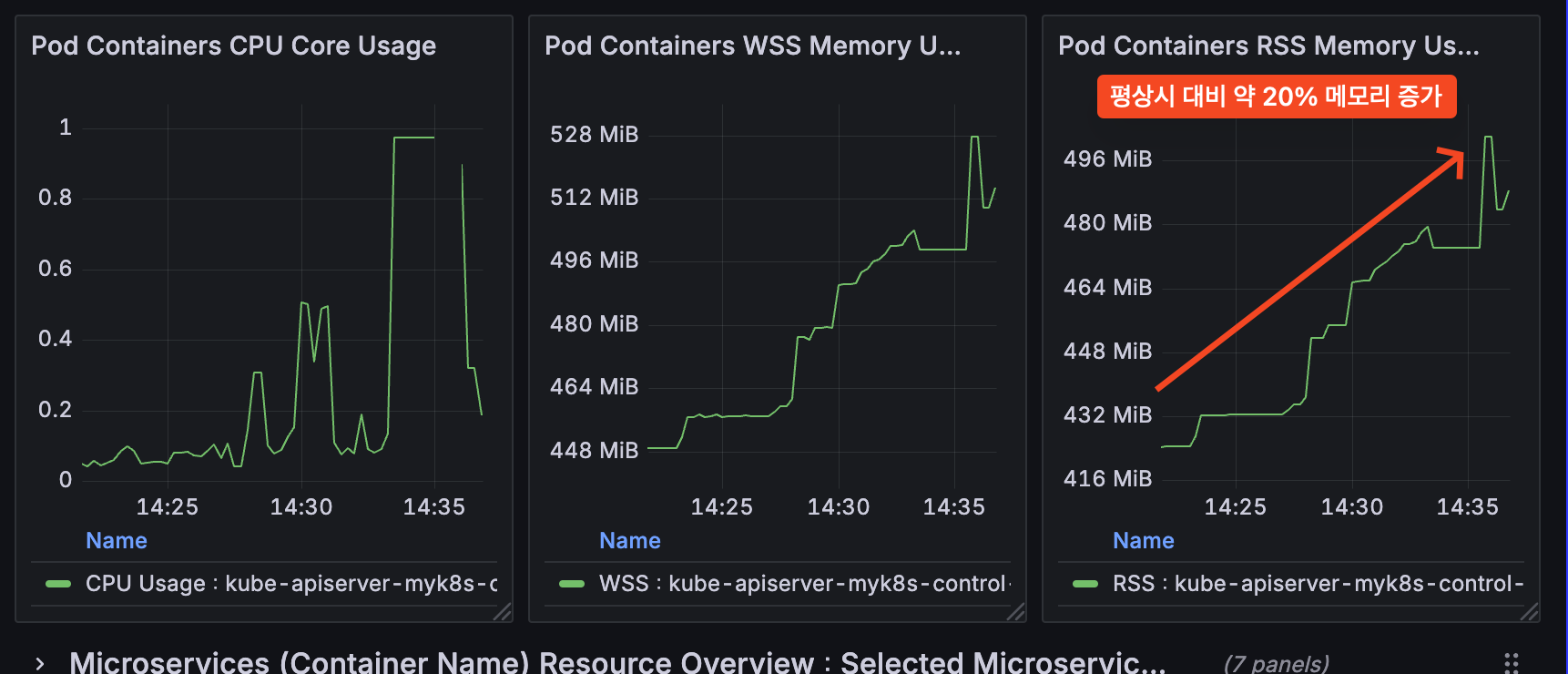
실제로 최근에 회사에서 클러스터에 다수의 워커 노드가 일시에 연결된적이 있었다.
- 실제로는 node kubelet 서비스가 한번에 enable 되었다.
그렇다보니 daemonset 그리고 deployment까지 최소 400개 pod이 일시에 생성되었고 이때 api-server가 죽는 장애가 발생했다.
문제의 원인은 동시에 많은 노드가 켜저서 -> pod 배포가 많고 -> api 요청이 많아져서 api-server의 부하를 유발하였다.
그리고 장애를 겪고나서 그럼 몇대의 노드를 일시에 킬 수 있는지, 몇대의 노드를 동시에 붙일 수 있는지에 대한 고민이 생겼다.
EKS docs를 보면 AWS에서도 xxx대의 워커노드를 한번에 연결할 경우, control plane에 부하가 생길 수 있다고 한다.

보통 pod을 배포할 때 pending이 걸리는 이유는 node 의 리소스 문제도 있지만, kubelet max pods, ip range의 문제도 있다.
node 객체를 확인해보면 podCIDR 필드로 /24 또는 사용자가 설정한 값이 설정되어 있다.
kubelet max pod을 무한정으로 늘리면, podCIDR가 부족한 문제가 생기기 때문에 적절하게(?) 설정하는것이 중요하다.
시나리오 3.configmap, secrets 등 다량 객체 일시 배포
가장 큰 부하를 유발하는 시나리오이다. 테스트에 필요한 deployment, secrets, configmap yaml을 생성한다.
--- 필요한 객체를 먼저 생성하고 ---
apiVersion: apps/v1
kind: Deployment
metadata:
name: deploy-{{.Iteration}}
namespace: api-intensive
labels:
app: api-intensive
kube-burner-job: api-intensive
spec:
replicas: 1
selector:
matchLabels:
app: api-intensive
instance: "{{.Iteration}}"
template:
metadata:
labels:
app: api-intensive
instance: "{{.Iteration}}"
kube-burner-job: api-intensive
spec:
containers:
- name: nginx
image: nginx:1.25
ports:
- containerPort: 80
---
apiVersion: v1
kind: ConfigMap
metadata:
name: cm-{{.Iteration}}
namespace: api-intensive
labels:
kube-burner-job: api-intensive
data:
key: "value-{{.Iteration}}"
---
apiVersion: v1
kind: Secret
metadata:
name: secret-{{.Iteration}}
namespace: api-intensive
labels:
kube-burner-job: api-intensive
type: Opaque
stringData:
username: "user-{{.Iteration}}"
password: "pass-{{.Iteration}}"
---
apiVersion: v1
kind: Service
metadata:
name: svc-{{.Iteration}}
namespace: api-intensive
labels:
kube-burner-job: api-intensive
spec:
selector:
app: api-intensive
instance: "{{.Iteration}}"
ports:
- protocol: TCP
port: 80
targetPort: 80
그리고 kube-burner를 통해서 통해서 동시에 api-server에 요청하도록 한다.
--- kube-burner 테스트 시작 ---
kube-burner init -c api-intensive-100.yml --log-level debug
---
jobs:
- name: api-intensive
jobIterations: 100
qps: 100
burst: 100
namespacedIterations: true
namespace: api-intensive
podWait: false
cleanup: true
waitWhenFinished: true
preLoadImages: false # true
objects:
- objectTemplate: ./deployment.yaml
replicas: 1
- objectTemplate: ./configmap.yaml
replicas: 1
- objectTemplate: ./secret.yaml
replicas: 1
- objectTemplate: ./service.yaml
replicas: 1
- name: api-intensive-patch
jobType: patch
jobIterations: 10
qps: 100
burst: 100
objects:
- kind: Deployment
objectTemplate: ./deployment_patch_add_label.json
labelSelector: {kube-burner-job: api-intensive}
patchType: "application/json-patch+json"
apiVersion: apps/v1
- kind: Deployment
objectTemplate: ./deployment_patch_add_pod_2.yaml
labelSelector: {kube-burner-job: api-intensive}
patchType: "application/apply-patch+yaml"
apiVersion: apps/v1
- kind: Deployment
objectTemplate: ./deployment_patch_add_label.yaml
labelSelector: {kube-burner-job: api-intensive}
patchType: "application/strategic-merge-patch+json"
apiVersion: apps/v1
- name: api-intensive-remove
qps: 500
burst: 500
jobType: delete
waitForDeletion: true
objects:
- kind: Deployment
labelSelector: {kube-burner-job: api-intensive}
apiVersion: apps/v1
- name: ensure-pods-removal
qps: 100
burst: 100
jobType: delete
waitForDeletion: true
objects:
- kind: Pod
labelSelector: {kube-burner-job: api-intensive}
- name: remove-services
qps: 100
burst: 100
jobType: delete
waitForDeletion: true
objects:
- kind: Service
labelSelector: {kube-burner-job: api-intensive}
- name: remove-configmaps-secrets
qps: 100
burst: 100
jobType: delete
objects:
- kind: ConfigMap
labelSelector: {kube-burner-job: api-intensive}
- kind: Secret
labelSelector: {kube-burner-job: api-intensive}
- name: remove-namespace
qps: 100
burst: 100
jobType: delete
waitForDeletion: true
objects:
- kind: Namespace
labelSelector: {kube-burner-job: api-intensive}
---테스트를 해보면 알겠지만, 일단 생성이 제대로 되지 않는다. 안된다기 보다 지연시간이 너무 길어진다.
그리고 중간중간 node cpu, memory 지표도 누락되고, job이 완료될때까지 한참 시간이 걸린다.
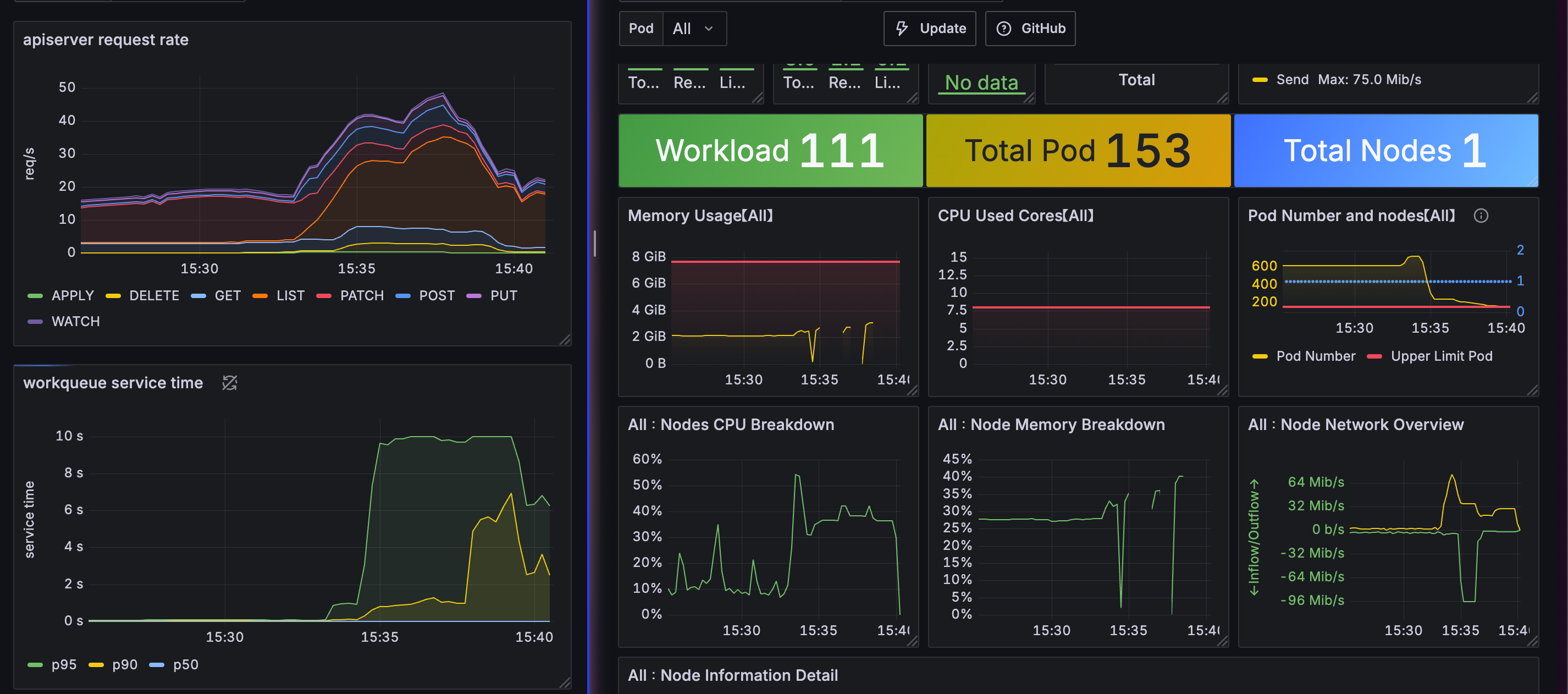
kube-apiserver 부하 줄이는 방법
EKS를 운영한다면 control plane에 대한 부담은 없다.
하지만 직접 k8s를 운영하는 입장에서는 kube-apiserver 부하를 줄이는 방법은 매우매우 중요하다.
부하를 줄이는 방법은 다양하게 있겠지만, 한가지만 소개하면 api 서버 flag와 APF가 있다.
API flag
qps와 관련된 kube-apiserver의 flag를 보면 --max-request-inflight와 --max-mutating-requests-inflight가 있다.
기본적으로 --max-request(기본값 400)는 get, list 등과 같이 상태를 조회하는 요청에 대한 제한이고
--max-mutating(기본값 200)은 create, update, delete와 같이 상태를 변경하는 요청에 대한 제한이다.
보통은 API flag로 api-server에 대한 전체 요청을 제한하기 보다는 APF 적요을 많이 권장한다.
- API flag는 모든 요청에 다 적용되기 때문에 kube-system 또는 기타 다른 중요 api에 대해서 제한이 될 수도 있다.
- 하지만 APF는 각 api 요청을 분류해서 개별적으로 제한을 할 수 있기 때문에 훨씬 유동적으로 설정이 가능하다.
PriorityAndFairness(APF)
k8s를 보면 flowshcema, priorityLebelConfiguration 객체가 있다.
쉽게 말하면 각 api-server에 대해서 resources, user 등 각 api 요청에 대한 queue와 비슷하다.

k8s에서는 상태 조회, 업데이트 하는 모든 요청을 kube-apiserver를 요청해서 처리하고, apiserver는 요청을 분류한다.

flowschema, priorityLevelConfiguration 두개 객체가 있어야하지 같이 적용이 되며, 기본값은 이미 배포가 되어 있다.
- 어떤 api 요청에 대해서 적용할지 정의를 하고, 어떤 queue config를 적용할지를 정의하게 된다.
worker 노드가 적고, pod 개수가 적다면 아마.. APF까지 고려해야 하는 상황은 없을것 가다.
하지만, 클러스터 규모가 커지면 커질수록 api-server의 리소스 사용량이 기하급수적으로 올라가기 때문에 대처가 필요하다.

APF에 대한 사례를 찾아보면 국내 사례는 많지 않고, 해외 사례는 종종(?) 있다.
그리고 해외 사례를 보면 대부분 cilium, calico 등과 같이 CNI에서 pod list 요청이 많아서 api-server oom 발생 사례가 종종있다.
- api-server의 요청과 kube-apiserver oom에 대한 관계를 다음 게시물에서 정리한다.
Kubernetes API and flow control: Managing request quantity and queuing procedure
How API Priority and Fairness can help your Kubernetes workloads? Here's a real-life case where its flow control features helped us bring a production application back to life.
blog.palark.com
실습 환경 구성(on cilium)
만약 cilium cni를 사용하고, 부하 테스트를 하려면 아래와 같이 kube proxy, default cni를 disable 해야한다.
kind create cluster --name myk8s --image kindest/node:v1.33.2 --config - <<EOF
kind: Cluster
apiVersion: kind.x-k8s.io/v1alpha4
nodes:
- role: control-plane
extraPortMappings:
- containerPort: 30000
hostPort: 30000
- containerPort: 30001
hostPort: 30001
- containerPort: 30002
hostPort: 30002
- containerPort: 30003
hostPort: 30003
kubeadmConfigPatches: # Prometheus Target connection refused bind-address 설정
- |
kind: ClusterConfiguration
controllerManager:
extraArgs:
bind-address: 0.0.0.0
etcd:
local:
extraArgs:
listen-metrics-urls: http://0.0.0.0:2381
scheduler:
extraArgs:
bind-address: 0.0.0.0
- |
kind: KubeProxyConfiguration
metricsBindAddress: 0.0.0.0
networking:
disableDefaultCNI: true
kubeProxyMode: none
podSubnet: "10.244.0.0/16" # cluster-cidr
kubeadmConfigPatches:
- |
kind: ClusterConfiguration
controllerManager:
extraArgs:
allocate-node-cidrs: "true"
cluster-cidr: "10.244.0.0/16"
node-cidr-mask-size: "22"
EOF그리고 default cni가 없기 때문에 cilium을 배포하기 이전에는 pod, node 상태가 비정상이며, cilium을 배포한다.
- natvie + direct node router 모드로 설정한다. 그리고 kube proxy를 대처하고 그외에는 특이사항이 없다.
- prometheus stack은 최상단에 정의한것과 동일하게 배포하면 된다.
cilium install --version 1.18.1 --set ipam.mode=kubernetes --set ipv4NativeRoutingCIDR=172.20.0.0/16 \
--set routingMode=native --set autoDirectNodeRoutes=true --set endpointRoutes.enabled=true --set directRoutingSkipUnreachable=true \
--set kubeProxyReplacement=true --set bpf.masquerade=true \
--set endpointHealthChecking.enabled=false --set healthChecking=false \
--set hubble.enabled=true --set hubble.relay.enabled=true --set hubble.ui.enabled=true \
--set hubble.ui.service.type=NodePort --set hubble.ui.service.nodePort=30003 \
--set prometheus.enabled=true --set operator.prometheus.enabled=true --set envoy.prometheus.enabled=true --set hubble.metrics.enableOpenMetrics=true \
--set hubble.metrics.enabled="{dns,drop,tcp,flow,port-distribution,icmp,httpV2:exemplars=true;labelsContext=source_ip\,source_namespace\,source_workload\,destination_ip\,destination_namespace\,destination_workload\,traffic_direction}" \
--set debug.enabled=true # --dry-run-helm-valuesCilium 부하 w. Cilium map
cilium에서 부하로 인해 발생 가능한 상황은 여러가지가 있겠지만, 가장 중요한 것은 map size이다.
만약 cilium을 kube-proxy를 대체하고, host routing을 사용하면 nat, conntrack, routing 등의 정보를 map으로 관리한다.
그리고 기본적으로 map은 노드에서 사용 가능한 메모리의 0.25%를 map으로 사용한다.
kubectl exec -it -n kube-system ds/cilium -- cilium status --verbose
--- cilium map 정보 ---
'''
BPF Maps: dynamic sizing: on (ratio: 0.002500)
Name Size
Auth 524288
Non-TCP connection tracking 65536
TCP connection tracking 131072
Endpoints 65535
IP cache 512000
IPv4 masquerading agent 16384
IPv6 masquerading agent 16384
IPv4 fragmentation 8192
IPv4 service 65536
IPv6 service 65536
IPv4 service backend 65536
IPv6 service backend 65536
IPv4 service reverse NAT 65536
IPv6 service reverse NAT 65536
Metrics 1024
Ratelimit metrics 64
NAT 131072
Neighbor table 131072
Endpoint policy 16384
Policy stats 65536
Session affinity 65536
Sock reverse NAT 65536
'''만약 map full인 상황이 발생하면 신규로 스케줄링이 되는 pod 또는 service에 대해서 업데이트 하지 못한다.
그렇기 때문에 nat를 할 수 없고, endpoint를 찾지 못하는 문제점이 발생한다.
보통 map full이 발생하는것은 conntrack map이 full이 종종 발생한다. 그리고 대응 방법은 2가지가 있다.
첫번째로 --set mapDynamicSizeRatio을 조정하는 것이다.하지만!! 유의해야하는건 이때 map flush가 발생한다.
그리고 map flush가 발생한다는 것은 기존 활성된 세션이 끊어지고, 서비스 순단이 발생하는것이다.
'''
extraArgs:
- --bpf-map-dynamic-size-ratio=0.01
'''
--- cilium status --verbose ---
kubectl exec -it ds/cilium -- cilium status --verbose
'''
BPF Maps: dynamic sizing: on (ratio: 0.010000)
Name Size
Auth 524288
'''
그리고 두번째는 --conntrack-gc-interval을 조정하는 것이다.
기본적으로 conntrack은 30초 마다 gc가 일어난다. 그리고 gc 주기를 조정해서 map full을 방지하는것이다.
다만 gc 주기가 너무 짧게되면 그만큼 gc가 자주 일어나기 때문에 cpu 오버헤드가 발생한다.
그리고 tcp timeout보다 짧게되면 실제로 효과보다는 오버헤드만 증가하는 단점이 생길 수 있다.
'''
extraArgs:
- --conntrack-gc-interval=10s
'''
--- cilium args 확인 ---
kubectl -n kube-system get ds cilium -o yaml | grep conntrack-gc-interval
'''
- --conntrack-gc-interval=10s
'''Cilium 부하 <-> kube-apiserver
cilium 1.18때부터 kube-apiserver를 복수개로 설정할 수 있는 기능도 추가가 되었다.
이전까지는 cilium에서 단일 kube-apiserver만 지정 가능했고, 단일 장애 포인트 지점으로 거론되었다.
하지만 1.18부터는 --k8s-api-server-urls 옵션을 통해서 kube-apiserver 지정이 가능하다.
- 하지만 현업에서는 대부분 kube-apiserver는 HA 구성을 위해 다수 구성하고, LB에서 VIP로 묶어서 사용하고 있을것 같고
- 그렇기 때문에 kube-apiserver 1대가 죽더라도, 다른 api-server를 사용하기 때문에 실질적으로 장애로 발전하지는 않는다.
이번 주차에는 k8s에 대한 성능 측정, 특히 kube-apiserver에 대한 부하 테스트와 성능을 올리기 위한 방법에 대해서 알아보았다.
최근에 회사에서도 kube-apiserver oom이 몇번 발생했었고, 이를 해결하기 위해 여러가지 사례를 찾아보고 적용도 해보았다.
- calico도 사용하고, cilium을 사용하는 클러스터가 있어서 cilium을 튜닝해보지는 않았지만
해외 사례에서도 cilium이 pod list 호출이 많다고 하고, 실제로 oom이 발생했을때도 pod list 호출이 많았다.
그래서 APF로 pod list를 제한했으나, 다음 kube-apiserver oom에는 calico group에 대한 호출이 많았다.
그래서 이렇게 호출이 많은 api-server 리소스에 대해서 매번 APF를 적용하는것이 맞을까? 하는 생각이 들었다.
애초에 클러스터 규모 산정이 잘못된게 아닐까? 마스터 노드 3대에 적정한 워커 노드는 몇대일까? pod 의 적정 개수는 몇개일까?
찾아보면 적정(?) 에 대한 이야기는 없다. 물론 어떤 시스템을 배포하냐에 따라서 적정을 판별할 수는 없지만,
openai는 수천대의 워커 노드를 운영있고, CSP 회사의 지인 왈보통 마스터 노드는 5대 내/외로 충분하다고 한다.
그러면 도대체 oom이 왜 발생하는것인가? 근본적인 해결책은 무엇인가? 클러스터를 규모를 줄여야 하는것인가?
요즘 이래저래 고민은 많은데, 깔끔하게 해결되지가 않아서 찝찝한 마음이 계속 있다.
퇴근하고서도 이런 방법이 있을까? 해외에서는 어떻게 할까? 찾아보지만 뚜렷하게 제시하는곳은 없다.
그래서 카오스 엔지니어링으로 실험을 하고 이에 대한 결과 측정을 하려고 한다.
말이 거창한 카오스 엔지니어링이지, 여라기 실험 상황을 가정해서 control plane에 대한 지표 결과를 측정하려고 한다.
그리고 이러한 지표를 기반으로 당사의 클러스터 규모를 정하고, 클러스터 운영 프로세스를 정할 때 참고하려고 한다.
IDC에 직접 쿠버네티스를 올려서 운영하는 곳은 많지 않을것 같지만
마스터 노드 oom으로 장애가 발생하는 곳이 있다면.. 댓글 남겨 주세요 ㅜㅜ 서로 의견 공유합시다!!

'기술 토론장 > [K8s] Kubernetes' 카테고리의 다른 글
| [Cilium][8주차] Cilium Security & CiliumNetworkPolicy (0) | 2025.09.06 |
|---|---|
| kube-apiserver oom 죽지 않기 w. APF (1) | 2025.08.31 |
| [Cilium][6주차] L7 Aware Traffic Management (0) | 2025.08.24 |
| [Cilium][6주차] Service Mesh Gateway API Support (1) | 2025.08.23 |
| [Cilium][6주차] Service Mesh Ingress Support (1) | 2025.08.23 |