최근 회사에서 kube-apiserver oom으로 장애가 발생한적이 몇번 있었다. 한번이 아니고..
그래서 kube-apiserver에 대한 로직과 oom를 조치하기 위한 방법을 몇가지 소개하려고 한다.
kubernetes 동작 방법
먼저 다들 아는것처럼 kubernetes은 크게 5가지로 요소로 구분을 한다.
- kube-apiserver, etcd, controller manager, scheduler 그리고 kubelet
이중에서 kubelet을 제외하고는 보통 control plane 노드에 떠서 동작을 한다.
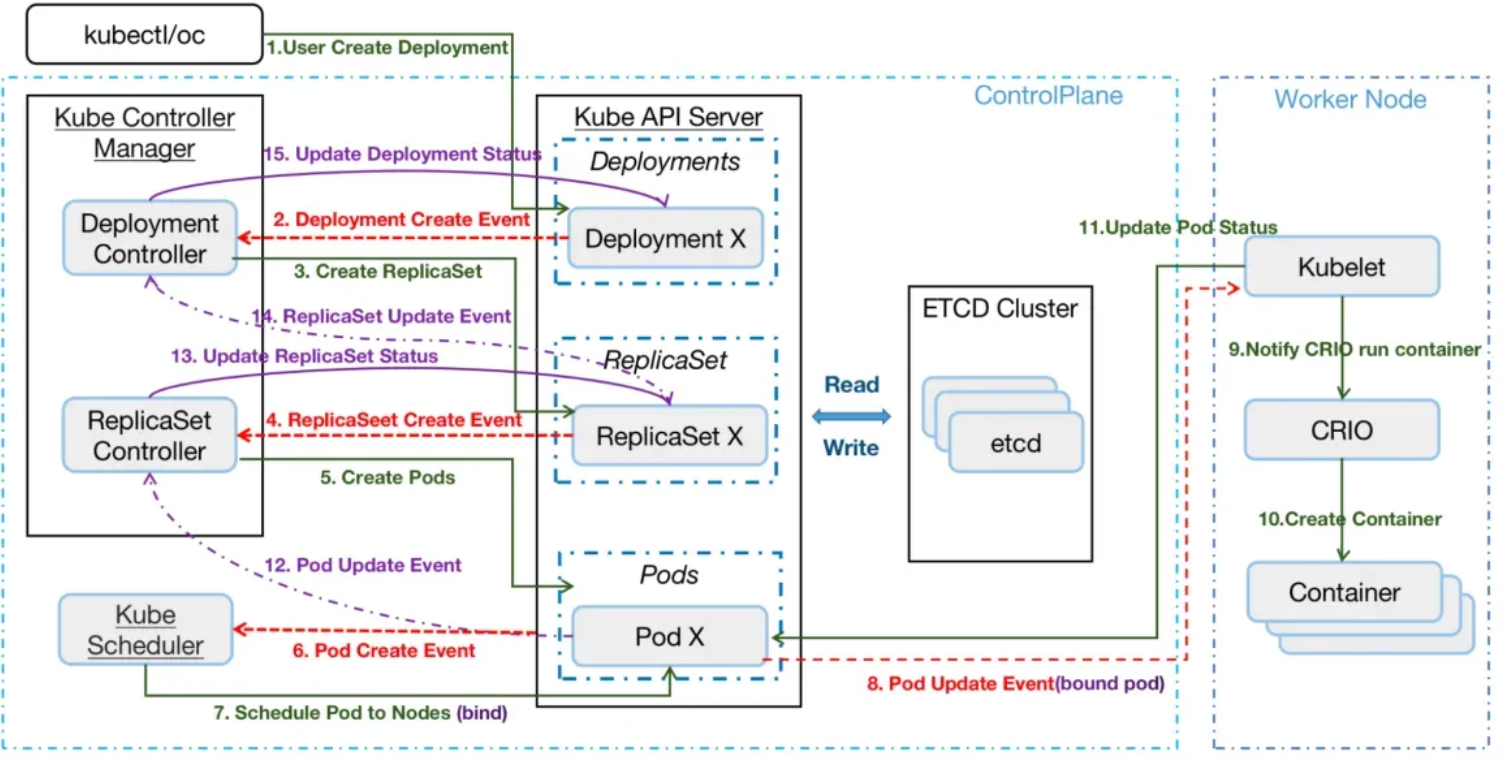
그리고 위 그림에 있는것처럼 controller manager, schedeler, kubelet은 저장소인 etcd와 직접 통신하지 않고
모든 통신은 kube-apiserver를 통해서 진행이 된다. kube-apiserver가 사람의 뇌와 유사하다.
사용자 또는 클라이언트가 k8s 객체 변경을 하면, kube-apiserver로 요청을 하게 되고 -> etcd에 저장을 한다.
그리고 controller-manager, scheduler한테 변경 이벤트를 주고, 최종적으로는 kubelet이 pod을 생성하고 다시 etcd에 저장한다.
kube-apiserver 동작 방법

kubernetes의 동작 과정을 조금 더 쉽게 도식화 한 그림이다. 그림에서 보면 "요청 감시"라는 단어가 많다.
controller-manager 등의 클라이언트들은 어떻게 kube-apiserver을 어떻게 "요청 감시"하는것일까?
해답은 watch 이벤트를 통해서 stream connection을 하기 때문이다.
kube-apiserver는 다음과 같은 데이터 흐름으로 클라이언트의 요청을 처리한다.
1. 클라이언트가 kube-apiserver에 데이터를 요청한다.
2. kube-apiserver는 etcd로부터 데이터를 조회한다.
- 이때 etcd는 단순히 key, values 이기 때문에, prefix(namespace) 단위로 전체 데이터를 조회한다.
- field-selector, labels-selector는 etcd 조회할때 하는것이 아니다.
3. kube-apiserver는 etcd로 부터 받은 데이터를 메모리에 올려서, 클라이언트 요청에 따라서 데이터 직렬화를 거친다.
- field-selector 등으로 필요한 정보만 etcd로부터 읽을수는 없다.
- kube-apiserver는 클라이언트 요청을 처리하기 위해서 빠르게 처리하기 위해서 요청마다 고루틴을 만들어서 병렬 처리를 한다.
3.1 만약 객체가 500개가 초과된다면, 3의 과정에서 continue 파라미터를 전달하고 다시 3의 과정이 반복된다.
- 이때 중요한것은 500개의 객체 정보만 메모리에 올라가는것이 아니다. 전체 메모리가 500개 초과되는 요청 개수만큼 올라가게 된다.
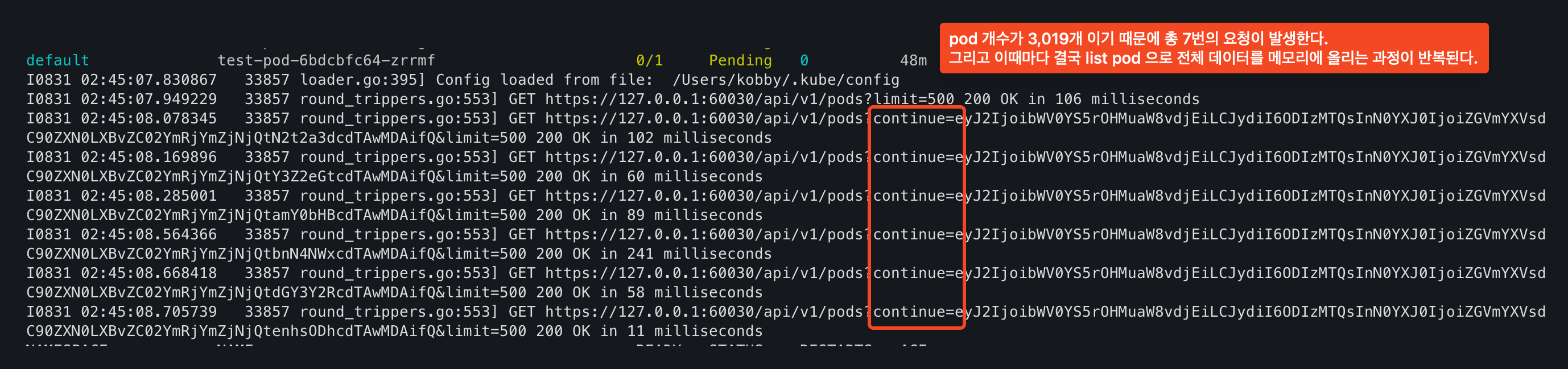
4. 클라이언트 응답이 모두 끝나면 메모리에 올린 데이터는 gc 주기에 맞춰서 메모리 해제가 일어난다.
- 메모리 해제가 즉시 이뤄지지 않기 때문에 대규모 LIST 요청이 반복되면 순간적으로 heap이 늘어나서 oom이 발생한다
부하 테스트 before APF
단순하게 nginx pod 개수를 늘려서 localhost /api/ve/pods을 해보면 3,000개 약 15.4MB 응답 크기를 나타낸다.
- 실제로 운영중인 클러스터에서는 약 10,000개의 pod이 있는데 조회해보면 응답 크기가 약 170MB 정도 된다.
| pod 개수 | 응답 크기 | 응답 시간 |
| 3,000개 | 15.4MB | 12초 |
| 2,000개 | 10MB | 7초 |
| 1,000개 | 0.7MB | 1초 |
그리고 seq, xargs를 사용해서, 동시에 요청하는 클라이언트와 전체 요청 개수를 늘려보면 요청에 따라서 메모리 사용량이 늘어난다.
seq 30 | xargs -n1 -P10 -I{} curl -s "http://localhost:8080/api/v1/pods?limit=3000" > /dev/null
테스트를 해보면 pod 개수 및 요청 개수 자체도 많은 편이 아니나 kube-apiservers는 1 ~ 1.8gib까지 점유하고 있다.
실 운영 환경에서는 각 노드마다 클라이언트가 다수 떠있고, 클라이언트 자체도 많기 때문에 이보다 훨씬 더 많은 부하가 발생한다.
그리고 테스트를 해보면 요청 개수보다는 동시에 얼마나 많은 클라이언트가 요청하는지가 더 큰 영향을 준다.
부하 테스트 after APF
그렇다면 이번에는 pod list에 대해서 api-server 요청 자체를 제한해보는 APF를 적용한다.
apiVersion: flowcontrol.apiserver.k8s.io/v1
kind: PriorityLevelConfiguration
metadata:
name: limit-pod-list
spec:
type: Limited
limited:
nominalConcurrencyShares: 5
limitResponse:
type: Queue
queuing:
queues: 5
handSize: 1
queueLengthLimit: 50
---
apiVersion: flowcontrol.apiserver.k8s.io/v1
kind: FlowSchema
metadata:
name: restrict-pod-list
spec:
priorityLevelConfiguration:
name: limit-pod-list
matchingPrecedence: 100
distinguisherMethod:
type: ByUser
rules:
- subjects:
- kind: Group
group:
name: system:authenticated
- kind: Group
group:
name: system:unauthenticated
resourceRules:
- verbs: ["list"]
apiGroups: [""]
resources: ["pods"]
namespaces: ["*"]중요한것은 PriotityLebelConfiguration에서 nominalConcurrencyShares의 값이다.
이는 kube-apiserver의 처리량을 상대적으로 비교해서, 해당 요청에 얼마나 많은 리소스를 부여할지를 의미한다.
상대적인 처리랑을 비교하기 때문에, 확인하기 어려운데 kubectl metrics을 보면 metrics으로 명확한 수치를 제공해준다.
총 12건의 요청을 동시에 처리할 수 있고, queue를 감안했을때 총 612개의 요청을 처리할 수 있다는 것을 의미한다.
kubectl get --raw /metrics |grep pod-list |grep seats ok | % | kind-myk8s/kube-system kube | 02:32:28
'''
apiserver_flowcontrol_target_seats{priority_level="limit-pod-list"} 12
apiserver_flowcontrol_upper_limit_seats{priority_level="limit-pod-list"} 612
'''APF를 적용하고 나서 동일한 부하 테스트를 해보면 APF 적용하기 전보다는 약 11% 메모리 사용량이 줄어들었고
nominalConcurrencyShares를 줄였을때는 메모리 사용량는 더 줄어들어서 적용 전보다 약 25% 메모리 사용량이 줄었다.

동시에 처리하는 요청을 제한하기 때문에 그만큼 메모리에 올라가는 데이터가 작아서 메모리 사용량이 줄어드는 것을 의미한다.
그렇다면 모든 요청에 대해서 APF를 적용하는것이 좋은가? 꼭 그렇지는 않다.
APF를 너무 작은 값으로 설정하게 되면, 정상적으로 운영에 필요한 요청도 제한이 될 수 있다.
특히 kube-system, kubelet 또는 시스템에 반드시 필요한 요청은 제한을하면 오히려 문제가 생길 가능성이 높다.
그래서 flowschema를 보면 우선순위가 적용되어 있다.
근본적으로 kube-apiserver가 oom이 발생하는 이유는 kube-apiserver가 처리하는 api 요청이 많기 때문이다.
api 요청은 get, list, create, delete 등의 verb를 있는데, 이중에서 list verb가 가장 큰 부하를 유발한다. 가장 응답 크기가 크다.
list verb는 watch stream connection을 하기 위해 먼저 호출이 되는 요청이다.
정리하면 watch connection을 요구하는 클라이언트가 많아지면 많아질수록 -> list 요청이 많고 -> kube-apiserver 부하가 커진다.
생각보다 watch connection을 요구하는 클라이언트는 많다. kube-proxy도 있고, calico, cilium 같은 cni도 있고
각 노드에 배치되어 있는 kubelet고 있고, prometheus와 같은 monitroing 시스템도 있다.
대부분의 사람들은 APF의 존재를 모를것 같다. 나도 지금까지는 몰랐다.
api-server가 oom으로 몇번 죽고 나니.. 대처방법을 찾기 위해서 APF를 찾아보고 적용했다.
APF은 resource, group, user에 대해서 적용하기 때문에 문제가 되는 요청 또는 부하를 유발하는 요청을 분류하는것이 먼저다.
분류를 하고 나서 -> APF를 적용하고 -> 동일한 부하 상황을 가정해서 테스트를 하고 검증을 해야한다.
하지만 해보면 알겠지만, 검증이 참 애매하다..
테스트 환경은 api-server가 oom이 발생할만큼의 환경을 만들기 어려워서 검증도 어렵다. 그렇다고 운영 환경에서 검증할 수도 없다.
그래서 테스트 규모를 확장해서 운영 환경과 가장 유사한 환경에서 테스트를 하거나
카오스 엔지니어링같이 실제 운영 또는 개발 환경에서 실험을 기획하고, 테스트하고 결과를 도출하는것이 중요하다.
'기술 토론장 > [K8s] Kubernetes' 카테고리의 다른 글
| [Cilium][8주차] Cilium end to end security + Tetragon (1) | 2025.09.07 |
|---|---|
| [Cilium][8주차] Cilium Security & CiliumNetworkPolicy (0) | 2025.09.06 |
| [Cilium][7주차] K8s, Cilium 부하 테스트 & 성능 측정 (1) | 2025.08.30 |
| [Cilium][6주차] L7 Aware Traffic Management (0) | 2025.08.24 |
| [Cilium][6주차] Service Mesh Gateway API Support (1) | 2025.08.23 |